��Implementing
EBT��
Author: Norman
MacLeod
2023-05-23
Table of
Contents:
2 Introduction Pilot Training and Pilot Learning
2.1 Piloting as Goal-directed Action
2.2 Pilot ��Knowledge�� is Retrospective
2.4 Error as Learning Feedback
3 The Development of Training in Aviation
3.1 How Humans (and Animals) Learn
3.6 Competencies in Civil Aviation
4 Implementing Instructional Systems Design
4.2 Developing the Job Task Analysis
4.3 Normal v Non-normal/Emergency
4.4 The Training Needs Analysis (TNA)
4.5 Describing the Output Standard
5 Developing Competence Frameworks and Markers.
5.2 Developing a Competence Model
5.6 Validating a Marker Framework.
6 Some Thoughts on the idea of ��Knowledge�� as Competence
7.2 Testing of Declarative Knowledge
7.4 Managing the Output from Tests.
8.3.2 Designing Event Sets to Create Surprise.
8.3.4 Training for Uncertainty
9.2 Reasons for Grading Performance
9.4 Constructing a Grade Scale
10.3 Observation of Performance
10.4 Assigning a Score to a Performance �C Sources of
Assessor Unreliability in Evaluation
11 Instructor and Assessor Training, Qualification and
Standardisation
11.2 The Training of Instructors
11.4 The Importance of Debriefing
11.5 Classical Debriefing Structures
11.6 ��Safety II�� meets Elite Team Sports
11.7 Diagnosis, Debriefing and Facilitation
11.8 Instructor Concordance Assurance
11.9 Calibrating the Grading System (AMC1/GM2
ORO.FC.231(d)(2))
12 System Safety and Evaluation
12.2 An Overview of Training Evaluation
12.3 Data Gathering and the SC
12.4 The Data-gathering Structure
12.10 Flight Data Monitoring (FDM) and Analysis
13.2 The Problem of Compliance
13.3 An Approach to CRM Training
14.4 Phase 3 - Programme Launch
15 The Safety Case - Managing Hazards and Risk in the
Training System
15.2 The Structure of the SC..
15.3 Constructing the Top-level Goals
15.4 Collecting the Best Evidence
1 Abbreviations
AQP Advanced
Qualification Programme
ATQP Alternative
Training and Qualification Programme
CBT Competency-based
Training
CBTA Competency-based
Training and Assessment
CF Competency
Framework
EBT Evidence-based
Training
EVAL Evaluation
Phase
FOI Flight
Operations Inspector
IP Implementation
Plan
ISD Instructional
Systems Design
ITQI IATA
Training and Qualification Initiative
LC Line
Check
LOE Line
Operational Evaluation
LOQE Line
Operational Quality Evaluation (see LOSA)
LOSA Line
Operational Safety Audit
LPC License
Proficiency Check
MT Manoeuvres
Training
MBT Manoeuvres-based
Training
NAA National
Aviation Authority
NGAP Next
Generation Aviation Professional
OFDM Operational
Flight Data Monitoring
OJT On-the-Job
Training
OPC Operator��s
Proficiency Check
OPS Operational
Performance Standard
SAT Systems
Approach to Training
SBT Scenario-based
Training Phase
SC Safety
Case
SME Subject
Matter Expert
TA Task
Analysis
TNA Training
Needs Analysis
TPS Training
Performance Standard
2 Introduction Pilot Training and Pilot Learning
Of the
billions of photons that strike the retina in the eye, only 40 per second are
processed by the brain. It seems
that the brain feeds forward an expectation of what the eye ��should�� be seeing,
which is then compared with actual data received by the eye and the brain then
attempts to resolve any discrepancies.
By implication, the version of the world we hold in our heads is
probabilistic, not a truth.
Furthermore, no two people can possibly hold the same version of the
world although their individual versions usually correlate sufficiently for
them each to think that they are looking at the same scene. But this is only a part of the problem.
Imagine
that you are at the controls of an aircraft. In your head you hold a version of the
status of the aircraft and, also, a model of how it will respond to any inputs
you make via the controls or through the automation. You have acquired this model through
training and experience. You now
make an input, the aircraft responds and becomes established in a new, stable
state. If the hypothesis outlined
above is correct, your interpretation of the new status of the aircraft is
equally probabilistic, not a truth.
Furthermore, the final status of the aircraft is just one of many
possible end states that could have been achieved. The cause-and-effect relationship
between your input and the outcome is no more than a hypothesis about how the
world will respond. The robustness
of your model of the world will influence the probability of achieving the
desired outcome but it cannot guarantee it for several reasons.
First,
aviation takes place in a dynamic environment and, as such, exhibits
non-ergodicity. In simple terms this means that there is an inherent volatility
in the world that guarantees that nothing ever happens the same way twice. Second, the world is complex. Again, in simple terms, complexity means
that aviation involves multiple agents but with no single controlling
authority. The component parts,
therefore, have a habit of acting in unexpected ways. Finally, the world exhibits radical
uncertainty, which is to say that things go wrong in ways we could never
anticipate.
2.1 Piloting as Goal-directed Action
When we
operate an aircraft, we follow a trajectory from flight initiation to aircraft
shut down. That trajectory
comprises a sequence of goals, each of which has a specific configuration that
allows the task to be achieved within the constraints of the laws of
aerodynamics. The pilot��s job is to
configure the device in accordance with the requirements of the specific target
goal, to manage transitions between goals and, occasionally, to adapt to
unanticipated circumstances that might require goals to be modified or new
goals created. This all takes place
in a space defined by legal, commercial and aerodynamic constraints. To illustrate the point let us look at
one small segment of a flight, the final approach. In very simple terms the task can described
as:

Each of
these goal states has a specific set of criteria that must be met for the goal
to be achieved. In addition, there
are specific processes that must be applied to achieve each goal and to
transition between goals. Outputs
from the aircraft��s Digital Flight Data Recorder (DFDR) allows us to explore
the way pilots manage this notional trajectory.
This
next graphic shows data from 301 Airbus pilots attempting to flare the
aircraft. The DFDR output for the
Pitch Angle parameter has been processed by an algorithm that looks at the
statistical relationship between data points. The central dark blue band shows the
most closely related 50% of data while the light blue bands show the outer 20% of
the distribution (some data is lost because it fails the test of statistical
significance). The bands show
the distribution of data from 300 pilots who flew a normal approach. The red line is the trace of the 301st
pilot whose performance is a statistical aberration. The trace of data from this flight
differs significantly from the cohort of 300 peers.
4 3 2 1
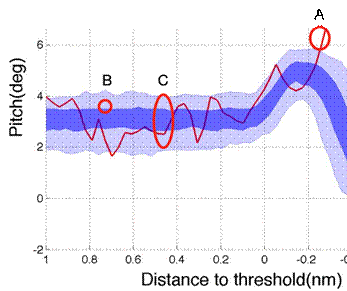
With
data, we can render the goal state model tangible. We can follow the aircraft��s status on
the final descent path (1), the transition to the flare (2), the aircraft
established in the flare (3) and, finally, the transition to the ��landed�� goal
(4).
But
this visualisation of normal data shows something more. First, we can see what happens
next. The Pilot 301 is initially
struggling to maintain the aircraft within the normal distribution but, at
Point A on the display, the aircraft��s path diverges. For whatever reason, Pilot 301 was
unable to maintain the aircraft within normal bounds. But that does not mean that the cohort
of 300 were perfect. The picture
shows us what happened next for the cohort, but it also shows us what didn��t
happen. They didn��t exceed the bounds of the normal distribution. Why not?
The
graphic is not simply an overlay of individual traces. It is a density plot of specific data
points, each of which is a function of several other factors but captured as a
value for a single parameter, in this case Pitch Angle. It can also be seen as a smart
graphic. We can interrogate the
array, and, for a specific point, we can trace several probable outcomes. For example, if we look at the area at
Point B, the circle encloses several related data points which represent the
Pitch angle of a cluster of aircraft at that moment in time. We can now trace those aircraft forward
to Point C and see the distribution of probable outcomes that relate to the
aircraft��s status at Point B.
Controlling for other variables, such as wind vectors, turbulence and
control inputs (all of which are captured in data and can be displayed), we can
start to understand why Pilot 301 followed an erratic path while the cohort of
300 did not. From a pilot training
perspective, we can start to understand how pilots can increase the probability
of achieving the desired aircraft status.
2.2 Pilot ��Knowledge�� is Retrospective
By
describing a flight as a sequence of goal states we can begin to examine the
knowledge base pilots draw on to constrain the range of probable outcomes. The criteria that apply to each goal
comprises what is known as declarative knowledge while the rules we apply to
manoeuvre between goals is known as process knowledge. The role of the aviation training system
is to provide sufficient declarative and process knowledge to allow a pilot to
operate an aircraft unsupervised.
But once a pilot enters productive service, we need to build upon that
foundation of retrospective knowledge and equip her with the skills needed to
cope with a world that is governed by the laws of probability. If aviation is to maintain its enviable
reputation for safety and airlines are to operate at maximum efficiency, the
system we use to train pilots must equip them to function in the world I have
just described. This means that the
training system must transition from one that is retrospective to one that is
prospective.
Retrospective
learning deals with the past. It
describes a set of known relationships that hold under the conditions
applicable at the time of sampling.
For example, if I was to ask what the capital of Germany is you would
say Berlin. But the accuracy of
that fact depends upon historical circumstances: Berlin has not always been the
capital of Germany. Equally, the
corpus of knowledge described by the EASA ATPL ground training curriculum
represents a set of decisions about historic artefacts and relationships. There is no empirical evidence to suggest
that the domain content prescribed by the syllabus possess any fundamental
worth. Retrospective learning
clearly has some value in that it provides what can be called underpinning
knowledge. But such knowledge is
only of use if it meets 2 criteria.
First, it must be capable of being generalised. This means that the specific information
taught must be capable of being recast as general principles that can be applied
to novel situations. Second, it
must be generative. The information
presented must be capable of supporting the creation of new knowledge. Retrospective learning can only go so
far in preparing pilots to cope with future challenges. Prospective learning, on the other hand,
supports adaptive behaviour capable of coping with the unknown.
2.3 Controlling the Future
The
concept of prospective learning is rooted in attempts to formulate models of
evolutionary development: how does learning contribute to an organism��s chances
of survival and, therefore, its opportunity to pass on its genes. It also has roots in Artificial
Intelligence. So, how must Machine Learning (ML) algorithms be written if
devices are to be truly ��smart�� rather than simply being better than humans at
a limited range of tasks. The
concept has many overlaps with existing models of learning but does offer some
useful insights.
There
are 4 aspects of prospective learning that we need to consider. First, an entity must demonstrate continual
learning, which is remembering those aspects of the past that are relevant
to the future. In ML, new code
over-writes old code and so ��forgetting�� is absolute, even of the old code had
some advantages. Equally, the very
first use of the term ��proactive�� was to describe how prior learning in humans
interfered with new learning. The
implication is that pilot training systems must be designed so that we encode
declarative and process knowledge in such a way that it supports future
action. Much aviation ground
training seems to be little more than baggage. Unless academic knowledge can be
complied (generalisable and generative) in such a way that it informs action it
is of little value and will be quickly forgotten.
This
idea leads on to the second requirement of prospective learning, which is causal
estimation. Recognising that
outcomes are probabilistic, not deterministic, causal estimation requires us to
learn the structure of relations that support decisions that maximise the
probability of the most desired outcome.
We gain an understanding cause and effect, hopefully, because of
training. But, as we gain
experience, we elaborate our repertoire of goal state criteria and action
rules. This, in turn, builds better
causal estimation. Training systems
need to draw attention to the cues in the environment that suggest flaws in our
causal estimation, often resulting in situations that overwhelm the pilot��s
sense-making abilities (think ��Air France�� and ��startle��).
Because
of the complexity of normal life, we need ways to improve the efficiency of our
search for relevant information.
Known as constraints, these are things like heuristics, biases
and our assumed knowledge of prior probability distributions (��priors��) that we
use to constrain the search space.
Of course, heuristics and biases will be flawed. Equally, a prior, in this context, is
simply a belief about what normally happens. The use of constraints need a critical
thinking control loop that gives feedback on the efficacy of our search
strategy.
Finally,
and interestingly, prospective learning includes curiosity, which is
action that informs future decisions, including future unmet situations. The EASA CBT Pilot Competence framework
describes ��Knowledge�� as a competence.
While both clumsy and untenable (see Chapter 4), the spirit of the
concept comes close to the idea of curiosity. From a prospective learning perspective,
investment in curiosity requires effort that will offer no short-term reward
but could result in a pay off at some future time. Time spent refreshing procedural and
technical knowledge might have little subjective utility when set against any
alternative uses of that time, but the curiosity concept suggests that an
investment will support better coping strategies when faced with novel
situations. Curiosity, importantly,
also describes investing in learning around a topic, going beyond the defined
curriculum, doing more than the minimum.
Curiosity captures the concept of intrinsic motivation in learning
theory. Students with intrinsic
motivation - that is, they are learning a topic because they have an interest
in it - tend to out perform students with extrinsic motivation. Extrinsic motivation describes
students following a topic because they have to: they need to tick the box.
2.4 Error as Learning Feedback
At this
point it might be worth saying something about error in learning. In simple terms, error reflects the
degree of fit between task demands and the action taken to satisfy the goal
requirements. Because there is some
buffering in the system, rarely is there a perfect fit between inputs and
outcomes. The system is constantly
adjusting to variations and perturbations.
Where action exceeds the system��s buffering capacity, the discrepancy is
noted as an ��error��. To illustrate
the role of error in learning I want to use another analogy from Machine
Learning. ML algorithms work on
datasets that have been divided into 2 parts. One part is used to train the algorithm
and the other part is then used to test if the algorithm works. Unfortunately,
while the algorithm can deal with problems that are found within the
distribution of the data used for training (In-distribution Learning), it will
struggle or fail when presented with a problem that is
Out-of-Distribution. Humans, on the
other hand, can cope with Out-of-Distribution learning.
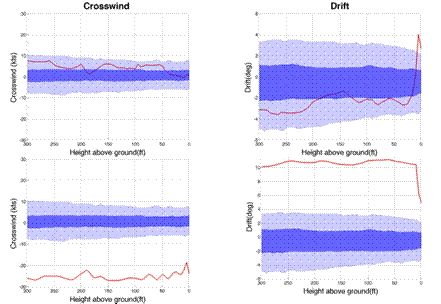
Consider
these 2 approaches. The first pilot (top) is encountering a crosswind component
that falls within the normal distribution of values experienced by the cohort
of 300 other pilots while the second pilot (bottom) encountered an
��out-of-distribution�� crosswind component (note that the scales have been
adjusted on the Drift presentation to accommodate the data):
Both
pilots have made an ��error�� but their responses are interesting. Whereas the first pilot seems to have
over-corrected for drift on touchdown, the response of the second pilot appears
to have been inadequate under the circumstances. Error, in this sense, is a feedback
signal. Whereas the first pilot is possibly fine tuning an existing model, the
latter will be elaborating on her model through exposure to a possibly novel
situation. In a prospective
learning context, error allows us to fine tune our causal explanation mechanism
and support continual learning through elaboration of the mapping between
stored knowledge and goal-directed action.
Out-of-distribution learning, which is a characteristic of human, rather
than machine, learning, is nonetheless brittle or fallible and, sometimes, the
price to be paid for the learning opportunity is catastrophic. Effective pilot training needs to allow
for out-of-distribution learning but in a safe context.
2.5 Conclusion
In this
Introduction we have set out a challenge for the pilot training system. Drawing on some concepts from other
domains, we have identified some criteria that a model of pilot learning must
satisfy. At the core of the model
is the need for pilots to cope with novelty. This has implications for the current
trend towards competency-based training.
Although
this Handbook has been developed to support Regulators and Operators wanting to
introduce EBT/CBTA to their training system, It is hoped that this Introduction
has offered some insights that will add value to the transition from legacy
training to the revised models.
3 The Development of Training in Aviation
3.1 How Humans (and Animals) Learn
New-born
infants to not emerge into the world completely unprepared to cope with what is
coming their way. We are a product
of evolution and certain behaviours seem to be transmitted genetically. For example, infants can orientate
towards faces while still in the womb and new-borns respond to voices ahead of
other sounds. Importantly,
new-borns appear to have the basic building blocks of associative learning.
Action
�C behaviour - involves 2 processing
systems: bottom-up and top-down.
The bottom-up system responds to stimuli in a fast, automatic manner
while the top-down system is slow and deliberative. Importantly, the top-down system
modulates the bottom up system based on information stored in memory. Hommel, in his Theory of Event Coding,
proposed that perceived and produced actions - what we see and what we do - are the same in that the
processing of inputs and the initiation of action flows from the same neural
paths. Watching others fires the
same neurones as if I was doing that work myself. This is the essence of mimicry. The candidate mechanism for the system
is the mirror neurone, first discovered in macaque monkeys and reported in the
mid-1990s.
This
fundamental framework underpins mimicry, the main way humans learn. Of course, as the human matures it
acquires experiences stored in memory.
When I act
with others, pre-reflective (that is, prior to conscious evaluation), bottom up
processing feeds forward signals.
These are largely derived from information stored in memory about the
task we are engaged in, who is supposed to be doing what etc. They create the world that I am expecting to see. Because we are social animals, other
people are a part of that world I am looking at. Because of the way the mirror neurones
work, their actions trigger the same responses in me as if I was doing what
they are doing. It is through this
process that can learn by watching.
3.2 Training Design
Mimicry underpins the way medieval guilds inducted apprentices into
their crafts. Unfortunately, it is
an inefficient model of learning. The roots of more structured approaches to
the development of training can be traced back to the American psychologist
Skinner. Working within the behaviourist tradition, Skinner elaborated the
concept of operant conditioning, which claims that learning can be influenced
by manipulating the learner��s environment.
Frame-based programmed learning, the model that still underpins most
computer-based training packages today, was the product of Skinner��s work.
The basic template for military
pilot training was established in 1917 with the formulation of what was called
the ��Gosport System��, which relied heavily on mimicry. In the intervening 100 years the
industry has experienced a series of catastrophic shocks, the solution to which
has typically been additional technology.
Mid-air collisions gave rise to TCAS; flying into the ground was cured
with GPWS; ROPS is intended to stop aircraft going off the end of runways. What has not really changed is how we
train pilots and yet the role of the pilot has been transformed from that of
controlling a device to managing a flight path.
In the 1950s, Benjamin Bloom published his Taxonomy of Intellectual
Behaviours (1956), producing the first hierarchical model of different types of
learning. Bloom identified 3 learning domains: Cognitive, Affective and
Psychomotor. The cognitive domain referred to the processes associated with
mental skills, the affective domain refers to attitudes and the psychomotor
domain encompasses physical skills. The legacy of Bloom��s work is the
tripartite Knowledge, Skill, Attitude (K/S/A) classification scheme still used
in training design today. Two former students of Bloom, Anderson and Krathwohl,
later developed the taxonomy by matching types of knowledge to types of
activities.
In 1962 Robert Mager established the concept of Learning Objectives as
the key building blocks of training design. Mager proposed that training should
be based on a clear statement of observable behaviour. It is important to
remember that the behaviourist tradition worked in terms of observed outputs
from mental activity, the mental aspect remains hidden from view. So, a
behavioural objective is a statement of what a student should be able to do as
a result of some mental process being accurately executed. Mager refined the
concept by adding the degree of accuracy required to be certain that the
performance was reliable. He also proposed that the conditions under which the
performance was to be enacted should be made clear. Mager��s work underpins the
��Performance, Standard and Condition�� structure of training objectives.
The contributions to the development of structured training have so far
concentrated on the identification and definition of training goals. In 1965
Robert Gagne published his ��Stages of Instruction��, laying down the framework
for the delivery of training. Gagne identified a set of conditions to be met
and some activities to be conducted that, combined, would lead to effective
learning. Gagne��s work shaped the way lessons are delivered in classrooms
today. Gagne was also one of the first to propose the application of systems
concepts to education.
This era was the time of huge investment in complex technological
projects such as nuclear power and manned spaceflight. In order to successfully
accomplish these projects, man and technology had to be enabled to work
effectively together. Many of the tools of modern management, such as project
management and structured decision-making, were stimulated by the demands of
these complex projects.
The first coherent model of structured training was probably that of
Robert Glaser, published in 1962 but it was the USAF ��5 Step Approach��,
published that same year, that brought the components of modern instructional
system design together for the first time. The 5 steps are:
• Analyse system
requirements;
• Define education
and training requirements;
• Develop objectives
and tests;
• Plan, develop and
validate training;
• Conduct and
evaluate training.
3.3 ADDIE
There have been various iterations of the basic 5 Step model and the
work of Florida State University, which published its ADDIE model in 1975, is
representative of the final stage in structured training systems development.
ADDIE stands for analysis, design, development, implementation and evaluation.
Whereas the 5 Step model was essentially linear in its conceptualisation, the
ADDIE model reflects a cyclical approach to training design in that the output
from training is constantly evaluated against operational need and changes made
as required.
Labelled the ��Systems Approach to Training�� (SAT), the model was widely
adopted by the US military and by many NATO countries. The Systems Approach to
Flying Training (SAFT) was used to reconfigure ab-inito pilot training in the
UK RAF in the early 1970s.
3.4 The Competence Concept
On 4 October 1957 the Soviet Union launched Sputnik, the first
artificial satellite to orbit the earth.
In one creation myth, this humiliation for the United States resulted in
the ��competence�� movement.
Recognising that simple course graduation was no guarantee of
proficiency, instead it was decised that there needed to be a framework for
demonstrating employability. In
1982, Richard Boyzatis published ��The Competent Manager: A model for effective
performance�� which is also credited with starting the competence movement Reflecting changes in the workplace and
society, with increased job insecurity and worker mobility, the competence
theorists attempted to identify core skills, or competences, that were suitably
generic and transferable between workplaces. For example, a steelworker might
possess a set of competences that would allow that person to find work in a
different sector of industry but only require minimal retraining. Competences
were reflected in vocational training courses in schools and higher education.
In the UK, competence frameworks were developed for commercial pilots and cabin
crew by the industry Lead Body although the associated National Vocational Qualification
for pilots lapsed because of a lack of uptake.
A competence framework comprises descriptions of desired workplace
behaviour arranged in clusters. Communications skills, people management and
team skills are the 3 most frequent competence clusters according to a 2007
survey. The behaviours are usually tagged with specific underpinning knowledge
required of the individual to support the demonstration of the desired
behaviour.
3.5 ISD in Civil Aviation
The recognition that the existing framework for training and checking
mandated by the FAA in the USA might not be guaranteeing the competence of
commercial pilots gave rise to the introduction of the Advanced Qualification
Program (AQP) in 1990. Pilot proficiency is typically assessed in terms of
manoeuvres repeated at prescribed time intervals. So, a set repertoire of
manoeuvres must be flown to pre-determined levels of accuracy and must be
demonstrated at set intervals. However, this ��one size fits all�� approach to
maintaining a competent workforce was increasingly being considered
inefficient. For a start, pilots acquire proficiency at different rates and
skills decay at different rates. Airlines operate into very different
environments with very different equipment and yet all have to meet the same training
requirements. The guiding principles of AQP are that each individual operator
must determine the skill set required of its pilots and that training and
checking must be based on the needs of individual pilots within the operational
context. The AQP regulations allow for the voluntary adoption of the program;
operators can continue to follow the manoeuvre/ interval-based, or ��legacy��,
model. The AQP concept has been broadened to include cabin crew and dispatcher
training.
Aware of developments in the US, the first draft of JAR OPS 1 included
line entries referring to AQP. The
promulgation of JAR OPS 1.978 - the Alternative Training and Qualification
Programme - in 2006 provided a framework for JAA �C later EASA - carriers to
adopt a training and checking regime based on line operations. The regulation
is built on the experience of AQP but incorporates developments in flight data
capture and analysis, safety management and auditing that have occurred in the
intervening period since AQP was first introduced.
We have just briefly sketched out the origins of structured models of
training analysis and design. From this it can be seen that ATQP is simply the
application of Instructional Systems Design (ISD) to commercial pilot training
and testing. In order to understand the significance of ATQP is necessary to,
first, review the existing framework for training and testing. In broad terms,
commercial pilot training comprises 4 phases: initial license training; type
conversion training; operator��s conversion training; recurrent training. In
addition, it is possible to distinguish 2 discrete aspects of the system. The
first is to train to a set standard. The second is to test competence, both at
the end of initial training and, again, at set intervals during employment.
Traditionally, the broad structure and content of the training course and the
criteria for success have been contained in regulations promulgated by national
authorities. The role of the airline training department is to configure
training in such a way that it demonstrates compliance with regulatory
requirements.
This model of training is pragmatic in the sense that it is rooted in
generations of operational experience and is successful in that aviation
remains a highly reliable, yet hazardous, industry. However, in a competitive
marketplace, training departments compete for resources with the rest of the
airline. As such, there is often little spare capacity to accommodate changes
in the operational world, such as the seasonal characteristics of operations or
changes in technology. The ��compliance�� model of training delivers a product
that meets regulatory demands but is not necessarily mapped onto the needs of
the specific airline.
3.6 Competencies in Civil Aviation
Recognising that the aviation industry faced a potential recruitment
shortfall across all sectors, IATA, through the ITQI, and ICAO, through NGAP,
have both been looking at introducing structured training models based on a
competence approach. Both are looking at a broader audience that just pilots
but the key difference, initially, was that ICAO were concerned that any
competence framework should cover initial selection and training as well as
in-service development and advancement.
The IATA project was the
first to bear fruit. In order to
break away from the historical ��set manoeuvre�� model, a large scale analysis of
various data sources was undertaken, resulting in the EBT Data Report. This provided ��evidence�� of what
training topics were more appropriate for modern generation aircraft. The goal of training was recast: no
longer did pilots have to demonstrate accomplishment in manoeuvres, they had to
demonstrate ��competence�� in the control of the aircraft, including the
management of the flight path under normal and non-normal circumstance.
One of the first
challenges was to define a ��competence��? Was it generic or specific? One school of thought suggests
that the manipulation of numbers and words and the ability to learn were
fundamental ��competences�� and all performance flows from these basic abilities. Another line of thought, discussed
earlier, took the view that competencies were arbitrary clusters of skill and
knowledge that were applicable to a specific work context. In effect, they are whatever you want
them to be as long as they make your workforce effective.
Another problem is the
interpretation of ��evidence�� in.
The current usage of the term ��evidence-based�� can be traced to a 1972 paper by
Archie Cochrane that questioned the effectiveness of medical treatments. Given the increasing costs of delivering
healthcare and the range of treatments available, how do you decide what works
best? The combinations of patient,
condition and treatment should be evaluated using Randomised Controlled Trials
(RCT) as the gold standard of evidence.
So, the ��evidence�� was what could be proven to work best. Other fields, such as social policy,
have adopted the concept but the underlying idea remains the same. In aviation, a direct analogy would be
an investigation of pilot experience level, skill to be trained and training
device employed. The closest we
have come to true ��EBT�� in aviation
are attempts to assess training transfer in flight simulators. Prof Inez de Florio-Hensen, at
Kassel University, argues that, in education, EBT is, in any case, an
unattainable goal. The range of
variables �C student, teacher, subject matter, training situation �C is simply
too great to make RCTs meaningful.
CBTA seems to be the application of ISD to initial training in all
specialisations while EBT refers to airline recurrent training.

3.7 A Career in Aviation
We can use the
trajectory of a pilot��s career (or any other employee) as an organising
framework to bring some of these concepts together. In the diagram above, the
trajectory starts with initial training for the award of a license. The input standard is usually a novice
with no skill or knowledge and the output standard is someone deemed fit to
hold a license. But a license
simply allows an individual to operate an aircraft appropriate to their
qualification. It does not
guarantee any level of expertise beyond a baseline level of safety.
As that
individual gains in experience they may want to start looking for a job. First, they need an aircraft type
rating. This involves applying
their prior learning to the specific instance of the new aircraft type. But they also need to convince an
employer that they are a good fit for the company. This is where a ��competence�� model comes
in handy. The employer knows that
the applicant is legal if they possess a license and the required ratings. The competence model describes the additional
attributes needed of the pilot to be successfully employed by that
airline. At the recruitment stage
the employer is simply looking for evidence of behaviour that maps onto the
competence model. In short, what
does the pilot bring with them that can be exploited and developed in their new
role?
As the pilot
progresses, 2 things need to happen.
From a legal perpective the airline needs to show that the pilot has
maintained the level of proficiency required to hold their license. From the airline��s perspective, the
pilot needs to show that they are capable of coping with the operational
demands likely to be encountered.
The airline needs to have a competence model that captures those demands
and sampling tool to evaulate the individual.
The pilot
lifecycle approach shows how we need different tools at different stages.
3.8 Is EBT a Flawed Concept?
Aviation Authorities
around the world have relied on the periodic accomplishment of a set of
manoeuvres as proof that a pilot is competent. Supporters of EBT argue that the event
set has failed to keep track with changes in technology and so a new way of
assessing is needed. It shoud be remembered that the State
has a legal duty to ensure the safety of its aviation system. The airline wants to be sure that its
pilots can do the job. The State
and the Airline have different goals but, historically, have used the same
performance measure.
EBT enthusiasts confuse
product and process. Product is the
observable output while process is how that output is achieved. The EBT argument is with the ��product�� �C
an anachronistic set of manoeuvres �C but ignores process. If a pilot can cope with the historic
manoeuvres then she can cope with any in-flight problem. At this point we need to go full circle
back to the beginnings of structured training design and ask what do we really
mean by skills and knowledge.
Stellan Ohlsson, in his book ��Deep Learning��, proposes that
expertise relies on an individual being able to establish a set of constraints
that must be satisfied for a particular condition to be considered true. Through training and experience we
develop an increasingly fine-grained set of constraints for an increasingly
varied repertoire of situations.
Process knowledge comprises the actions and rules sets we deploy to
satisfy the situational constraints.
Interestingly, he proposes that errors are, in fact, feedback signals
that tell us that a constraint has not been satisfied. In effect, either we have applied
inadequate constraints (faulty knowledge) or implemented an incorrect action.
The implications of
Ohlsson��s ideas are significant and
far-reaching. For a start, it is
not enough for a pilot to demonstrate the control of the aircraft to be
considered competent: they might have just been lucky on that day. We need to explore how pilots think
about control.
Competence, then, is
thinking made manifest. In the rest
of this manual we will look at how to achieve that goal.
3.9 Conclusion
We
can see 3 broad trends that have emerged since that first formalized flight
training system. Training is
expensive and so it has come under increasing pressure to be cost
effective. In order to achieve this
goal, systematic approaches to analysis and design have been implemented. Finally, steps have been taken to map
training onto operational need.
These last 2 themes form the structure of the rest of this book.
4 Implementing Instructional Systems Design
4.1 Introduction
The
starting point for both philosophies (AQP/ATQP and EBT) is a framework that
describes the range of performance we expect of pilots under all normal and
non-normal situations. AQP/ATQP follows the conventional ISD model and
starts with a Task Analysis (TA).
EBT, on the other hand, starts with a Competence Model (CM). The processes we use to develop both are
similar. The real difference is how
we describe performance, As we will
see later the eventual output from a TA is a syllabus of instruction. A CM is more akin to a job specification
or a set of Terms of Reference. In
both cases the final output needs to be a comprehensive description of the
performance expected such that we can be confident that we are able to verify
that pilots are competent.
The
main difference between the ISD-derived models and the competence approach is
that the former has a well-established process with well-understood methods
that can be applied to the task of develoing training. The competence approach, on the
otherhand, lacks any rigorous processes, in part because it was never intended
to be a design methodology.
This
chapter will deal with the ISD methodology while, in the next chapter we will
look at developing competence models.
2.2
The ADDIE Process Explained
The
ISD model, of which ADDIE is just one version, is a closed loop that starts
with analysis of requirements and comes back to the starting point via a number
intermediate of stages. The concept
is illustrated below. Because ADDIE
is refered to in the official documentation, we will discuss it within the
broader ISD context.
Step
1 is the Analysis phase. Here, we
look at the task required to be mastered by the trainee. We look a the
characteristics of the trainees, constraints on delivery, projet timescales
etc. Step 2 is the Design
phase. Here we define the output
standard. We do this now because
this will shape how much time is needed to train and what methods will be
needed to train and test. An output
from Step 2 is the syllabus. The
syllabus is usually framed as a set of learning goals or objectives that must
be achieved by the trainee. We will
look at objectives in more detail later. We also look at testing methods unde
the Design umbrella.
Having
described the syllabus, the next step is to do a Training Needs Analysis
(TNA). The TNA identifies the gap
between the Output Standard and skills mix of the entry level students. For example, an ab initio pilot just
graduating from a flight school will have a bigger gap between his current
status and that required at the end of a type conversion. However, an experienced pilot converting
from a different aircraft type will have a narrower gap between entry level and
output standard. The TNA will
inform the next step, which is curriculum design.
Analysis
Evaluate Implement Develop Design
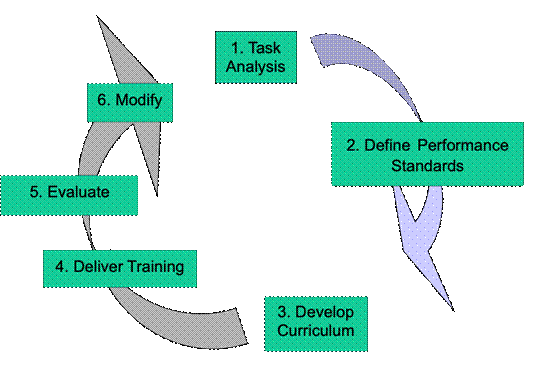
Although
useage does vary, I will use the syllabus to describe the course training
objectives and the curriculum to describe the allocation of objectives to
training events. Curriculum Development -Step 3- is where decisions are made about method
of delivery, training media to be used, time to be allocated, sequencing of
events and so on. It is where we do
the heavy lifting of making a course.
Then we have the Implementation phase. Implementation covers initial roll out,
prototyping, fine-tuning and bedding down the production version of the course.
It also includes trainer training and standardization.
Once
the course is up and running, we need to think about Evaluation. We look at this in more detail later in
the book but. Essentially, evaluation asks ��does the course work?�� If not, then we need a process for Modification.
4.2 Developing the Job Task Analysis
The
purpose of a JTA is to establish the baseline criteria for each job. The JTA
can be likened to a product specification for the conduct of duties and, as
such, has some similarity with a competence framework. The difference being that the TA is a
more fine-grained description of the actions associated with completing the
task. The TA will ultimately determine the instructional goals and objectives,
specify the type of knowledge required for the job, assist in determining
instructional activities and aid in constructing performance assessments. It
will also serve as the basis for auditing the company��s training
The
JTA, then, is exactly what the name implies; it is a list of actions associated
with the task for which an individual is responsible, stated in observable
objective statements. That is, each task should begin with a verb that
describes the nature of the activity associated with that task. For example, simply listing items to be
checked by a pilot is not a JTA. Instead, responsibilities should be listed in
terms of the observable action associated with that responsibility. For
example:
Poor task list:
1. engine oil
2. engine temperature
Acceptable task list:
1. check engine oil quantity
2. observe engine temperature
The
first step in developing the JTA is to compile a task list. There are several
ways to create a task list. One way is direct observation of the task. The
analyst observes a representative sample of the workforce and notes down job
behaviours as they occur. While this method works well because it takes place in
a naturalistic environment, it often does not allow the observer to catch all
aspects of the job. There is a view that the observer should be familiar with
the job, while others feel that a novice is best. The familiar observer may be
able to label tasks correctly and more accurately, but may bring their own bias
to the task. While a novice observer may not know the reasons for a particular
task, they are clear of procedural bias and assumptions.
Another
method for creating a task list is interviewing a Subject Matter Expert (SME).
It is best to include more than one SME for the interview process in order to
cover all situations and perspectives. The interviewer will typically ask the
SME to talk through the job out loud. The interviewer will want to ask questions
such as:
• What specific
duties must an employee perform?
• What units of work
must be completed?
• What handbooks must
be consulted?
Once
the task listing is complete, the next stage is to review each task to see if
there is a need for further decomposition. The task decomposition should not be
overly detailed such that the listing becomes cumbersome. Equally, it should
not be so vague such that it does not provide an adequate description of the
company��s requirements. There is a view that cut-and-pasting a JTA saves time. After all, an A-320 is an A-320 no
matter what the logo on the tail says.
In fact a JTA is specific to each company: no 2 airlines fly the same.
The
JTA is rooted in behaviourist psychology and, therefore, typically examines just
the observable behaviours needed to perform a job. However, some tasks require
non-observable behaviours, such as evaluative thought processes associated with
process control and decision-making skills. These types of behaviours can still
be represented in the task analysis but require an additional cognitive task
analysis. Table 2.1 briefly lists some types of task analysis and when to use
them. A common mistake is trying to force fit a job into a task analysis for
which it is ill suited.
Job/Performance
Used
for procedural skills
Learning/Needs Only
identifies what must be taught; secondary analysis
Cognitive Examines
how people think about situations
Content/Subject Matter Breaking
down large amounts of information into teachable
units
Table
2.1. Types of Task Analysis
There
is no ��ideal�� template for laying out a JTA. To a large degree it depends upon
the depth of analysis and intended use of the JTA within an airline. In an
integrated Safety, Quality and Training system, the content of the JTA will be
referenced to training records, crew scheduling, auditing and event reporting.
Therefore, it makes sense for the JTA to be built in a database product. Here
is one example of a JTA:
Takeoff Operations:
Normal Takeoff Procedure
Release Brakes
Align airplane on runway centreline
Transfer control of airplane to First Officer, if required
Call out": "YOU HAVE THE AIRCRAFT," if required
Call out": "I HAVE THE AIRCRAFT," if required
Maintain directional control with Rudder Pedal Steering and Rudder
GUARD Nose Wheel Steering until both engines stabilised and symmetrical
Advance Thrust Levers to approximately 50% N1
Ensure engines stabilised and symmetrical
Advance Thrust levers to FLEX or TOGA detent as required
Apply slight or full-forward side stick as required
Call out: "FLEX" or "TOGA" as required
Verify "FLEX" or "TOGA", SRS, and RWY (if
applicable) on FMA
Compare LP Rotor Speed (N1) to N1 rating limit on E/WD
Call out: "FLEX SET," or "TOGA SET" prior to 80
knots
Assume/Maintain Control of Thrust Levers
Call out: "80 KNOTS"
Acknowledge 80 knot call out: "CHECKED"
Remove forward side stick pressure at 80 knots to be neutral by 100
knots
Maintain wings level attitude with side stick
Monitor engine instruments
Call out: "V1" at V1 -5 knots
Remove hand from thrust levers
Call out: "ROTATE" at VR
At Vr, Rotate smoothly to SRS commanded attitude (or 110 degrees if no
SRS)
Call deviations from normal flight instrument indications
Call out: "POSITIVE RATE" (when a positive rate of climb is
indicated)
Ensure positive Rate of Climb
Call out: "GEAR UP"
Here is another example from a different airline for the same aircraft
at the same stage of flight:
1. Demonstrate the ability to perform a normal takeoff and initial climb
to flap retraction altitude in accordance with AOM and the company FOM.
2. Apply the appropriate CRM skills when performing a takeoff.
The JTA underpins the training development process and is fundamental to
the continued safe delivery of airline training. The JTA supports the Safety
Case (SC) (see Chapter 11) and also drives curriculum development. It is the
most time-consuming component of the ISD process. However, unless it is done
properly, it can also be the Achilles heel of the Training Department. Time
spent getting the TA correct will show a payback later in the implementation
phase
We
can develop a JTA, then, by inspecting documents, by observing performance and
by interviewing line pilots. We
could also look at safety reports and LOSA for evidence of poor performance
that can then be used to elaborate on the original analysis.
Table
2.1 shows a JTA that was developed for an Airbus operator. First, a number of management pilots who
were also trainers decided on a meaningful structure to describe the
performance of a pilot (Units of Work).
Next, the company Operations Manual, the aircraft FCOMs and the company
Flight Crew Training Manual were cross- referenced to the task structure. Rather than describe the job, references
were used for the sake of efficiency.
Each reference relates to a piece of documentation that describes the
task. Finally, experienced training
captains were asked to review the document and identify any gaps. The process looked at normal operations.
|
Unit of Work |
Baseline (SOP, FCTM) |
Probable Contingencies |
|
Pre-Duty |
OMA 5.2.1-5.2.3 (recency req.), 6.1 (medical fitness), 6.2 (medical precautions), 7 (FTLs), 8.1.12 (documents to be carried), 14.1.1 (documents to be carried by crew) , 14.1.2 (uniform) , 14.5 (crew bags) |
|
|
Dispatch |
FCOM: PRO-NOR-SOP-02 P1/6 |
|
|
Aircraft Pre-flight |
FCTM NO-020 P4/12-11/12 e-Library �C
Loadsheet ACARS PERF setup FCOM: PRO-NOR-SOP-03 P1/2 (safety exterior inspection), PRO-NOR-SOP-04 (power-up & before walkaround), PRO-NOR-SOP-05 (exterior inspection), PRO-NOR-SOP-06 (cockpit preparation), PRO-NOR-SRP-01-10 (cockpit preparation) |
|
|
Start/Pushback/towing |
FCTM NO-030 (eng
start) FCOM PRO-NOR-SOP 01 P9/20 (pushback & towing), PRO-NOR-SOP-07 (before pushpack or start), PRO-NOR-SOP-08 (engine start), PRO-NOR-SOP-09 (after start), PRO-NOR-SRP-01-10 (before pushback or start), OMA 8.3.20 (pre-taxi) |
|
|
Taxi |
FCTM NO-040 PRO-NOR-SOP-10 (Taxi), PRO-NOR-SRP-01-20 (taxi), OMA 8.3.21 (taxi) |
|
|
Take off/Rotation |
FCTM NO-050
P1-8/14 FCOM: PRO-NOR-SOP-11 (entering the runway), PRO-NOR-SOP-12 (takeoff), PRO-NOR-SRP-01-30 (takeoff), OMA 8.3.22 (takeoff) |
|
|
Initial Climb (to CLB thrust) |
FCTM NO-050 P8-13/14, FCOM PRO-NOR-SOP-13 (after takeoff), OMA 8.3.22.1 (climb graph) |
|
|
Departure (SID) |
OMA 8.3.23 (Departure and climb) |
|
|
Climb to cruise level |
FCTM NO-060 FCOM PRO-NOR-SOP-14 (climb), PRO-NOR-SRP-01-40, PRO-NOR-SRP-01-50 |
|
|
Cruise |
FCTM NO-070 FCOM PRO-NOR-SOP-15 (cruise) |
|
|
Descent preparation |
FCTM NO-080 FCOM: PRO-NOR-SOP-01 P15/20 (landing perf), PRO-NOR-SOP-16 (decent preparation), PRO-NOR-SRP-01-50 |
|
|
Descent |
FCTM NO-090 FCOM: PRO-NOR-SOP-01 P15/20 (descent profile), PRO-NOR-SOP-17 (descent initiation/monitoring/adjustment), PRO-NOR-SRP-01-60, OMA 8.3.25 (descent) |
|
|
Approach (STAR/Holding) |
FCTM: NO-100 (Holding), NO-110 P1-4/10 (Initial App), PRO-NOR-SOP-18, PRO-NOR-SRP-01-70 P1-3/32, OMA 8.3.25.3 (holding speed), 8.3.26 (approach) |
|
|
Final Approach |
FCTM: NO-110 P4-9/10
(final App), NO-120 (ILS), NO-130
(Non precision app) FCOM: PRO-NOR-SOP-01 P 15/20 (stabilized approach), PRO-NOR-SRP-01-70 P3-10/32, OMA 8.3.26.1 (stabilized approach) 8.3.26.2 (approach ban), 8.3.26.3 (ILS) |
FCTM NO-160 (LVO app), FCOM PRO-NOR-SRP-01-70 P11-23/32 |
|
Flare and Landing |
FCTM NO-170 e-Library �C
landing tips & Final Approach and Landing Technique FCOM PRO-NOR-SOP-19, OMA 8.3.27 (landing) |
|
|
Go Around/Rejected LDG |
FCTM NO-180 e-Library �C
Go-Around FCOM: PRO-NOR-SOP-01 P 16/20 (mandatory missed approach), PRO-NOR-SOP-20, PRO-NOR-SRP-01-80, OMA 8.3.28 (go around) |
|
|
Rollout |
FCOM: PRO-NOR-SOP-01 P17/20 (touchdown and rollout), PRO-NOR-SOP-21 (after landing) |
|
|
Taxi in and clean up |
FCTM NO-190 |
|
|
Shutdown |
FCOM PRO-NOR-SOP-22 (parking) |
|
|
Securing |
FCOM PRO-NOR-SOP-23 (securing the aircraft) |
|
Table
2.1 Airbus JTA
For
each element of competence, Subject Matter Experts (SMEs) were asked to
identify the range of contingencies that might apply in order to verify that
coverage was complete. We also
looked at differences between roles (PM/PF) and advancement (Command).
4.3 Normal v Non-normal/Emergency
Dealing
with non-normal or emergency procedures requires a different approach. Whereas normal operations follows a
distinctive, repetitious pattern (generally speaking), non-normal/emergency
situations tend to require a safety template to be overlain on the situation
which is then used to select an appropriate action. Competence in this sense might be
described in generic terms:
• Establish/sustain
control
• Evaluate
systems/flight path status
• Identify problem
• Identify
appropriate checklist(s)
• Execute checklists
• Validate system
response
• Choose next course
of action
• Monitor status
4.4 The Training Needs Analysis (TNA)
The
TA is a job specification. It describes the actions required of an operator if
a task is to be completed successfully. The goal of training is to develop the
skills of an individual so that they can complete the tasks in the TA without
supervision and to an acceptable standard. The first stage in developing a
course is to scrutinise the TA in order to identify those aspects of
performance that will need training.
Training
Need will be driven by the entry level of the trainees. An airline Initial Type Conversion
designed for ab inito cadets recently graduated from flight school will require
greater depth and content that an Operator��s Conversion course designed for
previously qualified pilots recruited from another airline. In the context of airline recurrent
training, it is unlikely that we will be developing modules with content tat is
completely novel. In most cases,
��training�� will be updating, adapting or linking to existing knowledge. Decisions about the depth of knowledge
and the time allocated to training will be influenced by this analysis of the
entry level.
For
each task we need to identify the skilled performance associated with the task
as well as any underpinning knowledge essential for successful task completion.
Underpinning knowledge will include an explanation of why the task is
important, any theoretical knowledge associated with completing the task,
probably risks attached to the task and any alternative strategies for task
completion.
4.5 Describing the Output Standard
Having
clarified the goals of the course, we now need to create the syllabus by
writing the Training Objectives (TOs). A TO typically comprises 3 parts:
A statement of performance.
A statement of the conditions under which the performance is to be
demonstrated.
A statement of the standard to be achieved for the performance to be
considered acceptable.
The
performance statement is worded in terms of observable actions using verbs. We
want to be able to witness the performance in order to assess the level of
achievement. Therefore, objectives describe the external manifestation of
competence. Because of the variability encountered during normal line
operations, any specific skill might be performed under a range of conditions.
The condition statement describes the range of contingencies under which a
trainee will be expected to perform in training so that we can be assured that
they will be able to cope with line operations. The standards statement defines
any bounds of acceptable performance we want to attach to each objective. A
standard might be a tolerance within which the skill is to be performed or it
might be a procedural limitation. An example of the TO might be:
Performance:
Land the aircraft
Conditions:
Within a range of crosswinds, at night, within a range of runway surface
conditions
Standards:
Within touchdown zone, within speed and ROD constraints.
These items drawn from the EASA HP&L syllabus illustrate weaknesses
in objective formulation:
a)
List the
factors determining pulse rate.
b)
Question the
established expression ��safety first�� in a commercial entity
c)
Describe the
personality, attitude and behaviours of an ideal crew member
Item a) is a valid objective.
Item b) starts with a verb but the rest of the performance statement
makes no sense. Is the student
supposed to question a safety policy in order to to elaborate on the entity��s
SMS? Is the aim to question the veracity of the statement in the first
place? Item c) collapses 3 possible
objectives into one and is a good illustration of ��signposting��. Rather than require students to declare any
knowledge in relation to the 2 key concepts - personality and attitude - it
suggests that there is a desired ��correct answer�� which, in any case, could
only be an opinion given the uncertain status of personality traits in relation
to pilot performance.
Writing TOs is as much an art as a science. Drafting acceptable TOs does require
skill so it might be worth looking at some examples to illustrate the
challenge. Appendix to Annex I to
ED Decision 2018/001/R offers this set of TOs in relation Mental Maths:
|
100 09 00 00 |
MENTAL MATHS |
|
Show, in non-calculator
tests and/or exercises, the ability in a time-efficient manner to make
correct mental calculation approximations: |
|
|
(1) |
To convert between
volumes and masses of fuel using range of units. |
|
(2) |
For applied questions
relating to time, distance and speed. |
|
(3) |
For applied questions
relating to rate of climb or rate of descent, distance and time. |
|
(4) |
To add or subtract time,
distance, and fuel mass in practical situations. |
|
(5) |
To calculate fuel burn
given time and fuel flow in practical situations. |
|
(6) |
To calculate time
available (for decision-making) given extra fuel. |
|
(7) |
To determine top of
descent using a given simple method. |
|
(8) |
To determine values that
vary by a percentage, e.g. dry-to-wet landing distance and fuel burn. |
|
(9) |
To estimate heights at
distances on a 3-degree glideslope. |
|
(10) |
To estimate headings
using the 1-in-60 rule. |
|
(11) |
To estimate headwind and
crosswind components given wind speed and direction and runway in use |
This example is clumsy and can be reframed thus:
|
Performance |
Condition (Common to all LOs: In an examination comprising x questions. Without the use of aids to calculation) |
|
1. Apply the 4 Rules of Number |
Using Whole Numbers, Decimals, Percentages. |
|
2. Convert between units of measurement |
Mass, Volume, Distance, Time. Given conversion factors |
|
3. Apply Rules of Thumb |
1 in 60 rule, Rule of Thirds (headwind and crosswind components). Lateral navigation (track, heading) Vertical navigation (height) |
We saw that the purpose of the TNA is to establish
what needs to be taught given the entry level of the students. Although
students will be expected to demonstrate the performance described in LO 1, we
can assume that they are already numerate and so no formal training will be
provided. Equally, we can assume
that our students understand the various terms such as ��mass�� volume, ��decimal��,
��percentage�� and so on so we do not need to offer training.
For LO3, however, some of the Rules of Thumb might
not be known to the class. In this
case we need to elaborate. So, in
this case we can consider ��Apply Rules of Thumb�� to be the Terminal Objective
(TO) and we would create some Enabling Objectives (EO) that allow the student
to achieve the TO.
|
Performance |
Condition |
|
3.1 State the 1 in 60 Rule |
in relation to: Lateral navigation Vertical Navigation |
|
3.2 State the Rule of Thirds |
In relation to: Heading Groundspeed |
In this example, the 3 TOs all describe what would be called a ��skill��,
in this case the mental manipulation of values. TOs are traditionally divided into 3
categories: skills, knowledge and attitudes. Skills are what you ��do�� while
��knowledge�� is what you know. There
are no ��attitude�� objectives contained in the table. We might decide that an attitude
objective is appropriate in this case.
So, we might consider these as candidates:
a)
State the
reasons why a ��gross error check�� on outputs is needed when entering data into
aircraft systems
b)
List the
reasons for conducting a ��dead
reckoning�� cross check on aircraft performance
Attitudinal objectives are recognised as difficult to define and almost
impossible to test.
4.6 Conclusion
In this chapter we have looked at ISD as a model of training design and
have differentiated between ISD as a process for designing inputs to bring
about behaviour change and the use of ��competencies�� to describe workplace
performance. The remaining steps in
ISD wil be covered in the following chapters.
5
Developing Competence
Frameworks and Markers.
5.1 Introduction
In
Chapter 1 we look at various models of training design. A key difference between classical
approaches to training design and the competence approach is that the former
addresses a specific job or task whereas the latter supposedly is designed to
develop a ��generic�� set of behaviours that can be transferred between different
jobs. For example, there might be a
range of different workplaces that all require an ability to make ��decisions��. If I have a fundamental
��decision-making�� toolkit then it doesn��t matter if I am an office clerk or an
astronaut, I can still have a go at making a decision. The complexity of the decision to be
made and the consequences of failure may differ but the process remains the
same.
Whereas ISD, then, looks at the interventions needed to bring about a
change in performance, the competence concept really looks at workplace
performance: can someone do a job?
To a degree, ��competence�� is blind to prior training. It isn��t interested in how a candiate
got here, just can that person do the job.
There are some conventional ISD concepts that can help clarify the
differences beteen the approach. In
any training system there are constraints on what can be achieved in the time
and resources available and the scope of the training system in terms of
workplace performance. The output
from training is usually described as the Training Performance Standard (TPS)
and recognises that there is a gap between that and the Operational Performance
Standard (OPS). The OPS, in fact,
equates to the level of competence expected of a person in productive
employment. The gap between TPS and
OPS can be bridged by formal programmes of On the Job Training (OJT), mentoring
or simply informal development through exposure to the real world. The TPS is usually specified in ISD �C it
is the graduation standard �C but the OPS is often left undefined.
To illustrate the problem, consider this OB from the Communication
competence:
OB 2.8 Uses and interprets non-verbal
communication in a manner appropriate to the organisational and social
culture (my emphasis)
In the 100KSA (2018) Communication requirement this has been elaborated
as:
09) Show the ability to correctly interpret
non-verbal communication.
10) Show the ability to use appropriate eye
contact, body movement and gestures that are consistent with and support verbal
messages.
The OB relates to non-verbal communication in a very specific context:
in relation to the organisational and social culture. The 100KSA elaborations establish an
expectation - correctly, appropriate, consistent, supporting - without making
clear what training inputs might be required nor how a trainee can meet these
expectations. Nor does the 100KSA formulation address issues of organisational
and social culture.
In theory it ought to be possible to trace a line from the initial
ground training requirement, through the practical application to achieving the
final operational assessment. The
piecemeal approach to developing commercial pilot training is still some way
off that goal. The TPS, then, should identify a set of generic
performance elements that broadly map onto the OPS. The TPS should describe
both activities and underpinning knowledge that supports the activity described
in the OPS.
One
problem we have is that we also need a mechanism for assessing
performance. It is important to
understand that a competence model and an assessment framework are not the same
things. The ��problem�� is that they
may overlap and share terminology.
In this chapter we explore some of these issues.
5.2 Developing
a Competence Model
Although there are well-defined activities associated with the ISD
process, developing competencies is less well supported. The paradox of EBT is that it claims to
be moving away from ��task-based�� assessment but being ��competent�� is
fundamentally based on doing tasks.
However, implicit in the competence approach is that performance is
abstract �C generalisable across different work contexts �C and aimed at
maintaining control of tasks, especially in uncertainty. Competencies try to guarantee control.
The UK Chartered Institute for Personnel and Development makes the
following points about competencies:
They ��focus on someone��s personal attributes
or inputs. They can be defined as the behaviours (and technical attributes
where appropriate) that individuals must have, or must acquire, to perform
effectively at work.
[��[ are broader concepts that cover
demonstrable performance outputs as well as behavioural inputs. They may relate
to a system or set of minimum standards needed to perform effectively at work.
A ��competency framework�� is a structure that
sets out and defines each individual competency (such as problem-solving or
people management) required by individuals working in an organisation��.
��In designing a competency framework, care
should be taken to include only measurable components. It's important to
restrict the number and complexity of competencies, typically aiming for no
more than 12 for any particular role (preferably fewer), and arranging them
into clusters to make the framework more accessible for users. The framework
should contain definitions and/or examples of each competency, particularly
where it deals with different levels of performance for each of the expected
behaviours. It should also outline the negative indicators for that competency
competency �C the behaviours deemed unacceptable��.
Importantly, there is no single, universal solution to this idea of a
competence model, nor is there is a single way to develop them. Organisations need to develop a model
that supports their commercial and operational goals. Competence models are useful because
they make clear to employees what is expected of them in any particular job or
role. This is why they should be
framed in the language of observable behaviour. A competence model also directs attention
to training requirements. A person
cannot be expected to do a job if they have not been properly trained. However, if you look again at the
extracts above, it does talk about behaviours that individuals must have or
acquire. This last point is
significant. The ��must have�� items
can be dealt with by recruiting people who have done the job before or through
pre-employment training. Acquiring
competence, as we saw erlier, can be done through structured workplace
development. Which brings us to
EBT. If you scratch the surface of
the EBT concept, what we are really talking about is a process of structure
workplace mentoring aimed at sustaining and developing a pilot��s ability to
cope with operational demands. It
is not really training at all.
The rise of CBT/EBT coincided with the discovery of ��Black Swans�� -
catastrophic but unpredictable events that we still need to be able to cope
with. Although, by definition, we
cannot train to deal with ��Black Swans��, we can still use the concept as a
jumping off point. There are 2
other, more common, properties of the world we need to consider: non-ergodicity
and radical uncertainty. The first
describes how things never happen the same way twice and the second relates to
how things have a tendency to fail in ways we never anticipate. So, a competent pilot must be able to
cope with a constant level of perturbation in the workplace (think ��threats, if
it helps) and, should something happen, then be able to restore an acceptable
level of control as quickly as possible.
In terms of ��competence��, we can illustrate the situation like this:
A problem we face with
developing competencies is that, often, behaviour is based on deeper,
underlying processes that occur internally. Behaviour is just the manifestation of
these processes. It could be argued
that true ��competence�� is really these behavioural precursors. The table below proposes a number of
target precursors.
|
Competence |
Supporting Activities |
|
Analysing |
Causal analysis; risk
appraisal; establish the gap between observed and expected; establish
abnormal cues based on mental model; compare assumptions about cause and
effect relations among cues |
|
Planning |
Identify options;
establish operational constraints; clarify remaining
capability/functionality; planning for contingencies |
|
Organising |
Identify actions required;
establish resources required; implementing contingency plan |
|
Validating |
Referencing observed
behaviours to expectations; establish deviations from normal state; use
critical thinking |
|
Deciding |
Validate rule set; identify information requirements;
validate efficacy of option; establish time reuirements |
|
Communicating |
Use proper phraseology :
pay attention to completeness of standard reports; seek
information/clarification/ check understanding; exchange information and comprehensions
to establish a shared understanding of the problem; formulate and communicate
hypothesis about cause and effect relationships |
|
Collaborating |
Monitor, support others,
provide guidance and suggestions; states appropriate priorities; update situation
periodically; resolve opposing interpretations based on team conflict
resolution |
|
Coping |
Create space and time;
control stress |
5.3 Assessing
Competence
Assessment of performance
is highly problematic. The tools we
use �C marker frameworks �C must meet 2 criteria if they are to be considered
useful. First, a category must meet
the requirement of validity.
Validity is the degree to which the tool measures the target
attribute. Second, the tool must be
reliable, which is the extent to which it is dependable across time. So,if I assess a candidate at time 1
then, assuming no change in performance, the score from an assessemtn at time 2
should be the same.
The competencies listed
above are precursors to performance.
They act in combinations to generate the workplace behaviours that are
accessible to observation and, therefore, assessment. This has implications for validity. How can I be sure that my observational
category is directly linked to the underpinning precursor. The more direct the relationship the
better the validity. It is for this
reason that ��Situational Awareness�� is unlikely to have verifiable validity as
a marker. The relationship between
competencies and outputs is suggested in the diagram below
Competence Marker
Analysing
Planning Application
of Procedures
Organising
Validating Management
of Systems
Deciding
Communicating
Task
Management
Collaborating
Coping
Fig.
3.1 Relationship between a Competence and a Marker
5.4 Competencies v Markers
A
competence framework is an attempt to describe all the skills and underpinning
knowledge required of an individual filling a role in an organisation. The idea is that the role is larger than
the specific ��job��. Someone can be
accomplished in their ��job�� but can still be lacking in overall
effectiveness. Historically,
specific job-related requirements would be described by a task analysis. Role-related requirements are covered,
in part, by the Job Description or Terms of Reference. However, Job Descriptions etc typically
only covered a minimum sub-set of what was required to be fully effective in
the role. The competence framework
attempts to bridge the gap by, first, more fully describing the role and then
by elaborating on the performance required in the role. A ��behavioural marker�� is a description
of an element of competence that can be observed in the workplace. The relationship between the 2 concepts
is illustrated in Fig. 4.1
5.5 Designing Markers
It was said earlier
that a competence model is not the same as an assessment framework. Assessment under EBT (and also the
earlier CRM requirement) is based on using observable behaviour as the evidence
on which to judge ��competence��.
Thus, whereas a competence model is a broad description of expectations,
an assessment framework is a subset of competence that can be routinely
observed in the workplace. Below is
an example of an assessment framework:
The NOTECHS Behavioural Markers
Categories Elements
Example
Behaviours
Co-opERATION Team
building and Establishes
atmosphere for open
maintaining communication
and participation
Considering others Takes
condition of other crew
members into account
Supporting others Helps
other crew members in
demanding situation
Conflict solving Concentrates
on what is right
rather than who is right
LEADERSHIP AND Use
of authority and Takes
initiative to ensure
MANAGERIAL SKILLS assertiveness involvement
and task completion
Maintaining standards Intervenes
if task completion
deviates from standards
Planning and coordinating
Clearly
states intentions and goals
Workload management Allocates
enough time to
complete tasks
SITUATION System
awareness Monitors
and reports changes in
AWARENESS system��s
states
Environmental Collects
information about the
awareness environment
Anticipation Identifies
possible future problems
DECISION MAKING Problem
definition / Reviews
causal factors with other
diagnosis crew
members
Option generation States
alternative courses of
action
Asks other crew member
for
options
Risk assessment / Considers
and shares risks of
Option choice alternative
courses of action
Outcome
review Checks
outcome against plan
There are 3 common
methods used to construct assessment frameworks. In aviation, probably the earliest
framework was the NASA/University of Texas Crew Effectiveness Marker
system. This was developed by
looking at a range of fatal aircraft accidents and identifying what behaviours
contributed to crew failure. This
method could be called the ��historical�� approach. The NOTECHS framework illustrated above
was developed by a committee of SMEs. The EASA framework is,
similarly, the output from a committee.
A third approach is to interview line pilots to get their views. By using structured interview techniques
and ��card sort�� techniques it is possible to develop an ecologically valid
assessment framework. An example of
such an approach is given here:
1. COMMUNICATION
This dimension
relates to the way in which an individual communicates. It includes the extent to which the
speaker is clear, easy to understand and unambiguous.
Positive indicators
include:
The sharing
information and prior experience, actively seeking opinions, giving input not
just when requested but also proactively. Positive responses to inputs
(acknowledgement, repeating messages).
Negative indicators
include:
The failure to
listen or ignoring information.
Failure to explain decisions, actions, intentions. An unwillingness to
communicate (needs constant prompting or repeated requests). Failure to check misunderstood
communication (demonstrates hesitancy or uncertainty).
2. TASK MANAGEMENT
This dimension
relates to the conduct of the task. It includes the consistent and appropriate
use of checklists and procedures.
Making effective use of time. The avoidance of distraction and
maintaining the bigger picture of things happening around the aircraft.
Positive indicators
include:
A consistent, but
flexible, use of SOPs. Monitoring the use of checklists during
busy periods and the positive verification that tasks have been completed.
Maintaining an even tempo of work (no unnecessary haste or urgency). Recognising when to minimise
non-essential conversation.
Maintaining awareness of other aircraft, objects etc around the aircraft
both in the air and on the ground.
Actively developing mental pictures of what to expect during the next stage of
flight (e.g. through verbalisation of expected landmarks, events, system
changes etc). Anticipation and thinking ahead. Being aware of time
available/remaining, being aware of things around the aircraft (in the air and
on the ground), verifying geographical position.
Negative indicators
include:
Too strict an
adherence to or rigid application of SOPs.
Spending too much time out-of-the-loop on admin tasks, failure to update
on events when off-frequency. Rushing or delaying actions unnecessarily
3. TEAM BUILDING
This dimension
describes the extent to which effective working relationships are established
and maintained within the crew. It includes behaviour which binds the team and
which establishes a task focus.
Positive indicators
include:
Setting the
tone. Clarifying expectations and
standards of performance. The recognition that others have a part to play in
the crew process. Clear allocation
of tasks and responsibilities.
Briefing any excursions from SOPs. Fostering a sense of comfort and
inclusiveness in the group.
Negative indicators
include:
Avoiding
responsibility for actions, preventing full expression of views, intolerance,
failure to allow individuals to fulfil their role, interference in the work of
others.
4. PLANNING AND DECISION-MAKING
This dimension
relates to the way crews go about making decisions and agree upon appropriate
courses of action.
Positive indicators
include:
Sharing problems
and concerns, clarifying plans, identifying and discussing options and
alternatives. Evaluating risks,
pointing out errors of thinking, explaining decisions, seeking agreement on
courses of action.
Negative indicators
include:
Hasty reaction to
events, failure to consider alternatives, failure to discuss solutions,
over-reliance on other agencies.
5. INTERACTION STYLE
This dimension
relates to the way crew members interact with one another. It includes an individuals�� personal
style, their way of dealing with others and their approach to the task.
Positive indicators
include:
An optimistic,
positive approach to the job, friendly and approachable. Personable and easy to get on with. Patient with others, sensitive to their
needs and open to feedback.
Conscientious and dependable (can be relied upon to do the job).
Negative indicators
include:
Overbearing,
confrontational, aggressive. Prone
to getting upset when things go wrong.
Sometimes lacking in confidence, timid or given to inappropriate
behaviour (e.g. poor use of humour).
Lacking in skills and unstructured in their approach to the job. Too relaxed or too rigid application of
the rules. Inflexible.
It is important to
remember that assessment must be appropriate to an airline��s needs. The competences required of a business
jet crew, compared to a cargo crew or a wide body ULH passenger crew will
differ. Markers are abstract
constructs that attempt to capture an aspect of behaviour that is deemed
important to the operation.
5.6 Validating a Marker Framework.
The 2 examples of
marker frameworks illustrated above contain a broad statement of a behaviour - ��Cooperation��,
for example - and then some elaboration in the form of example behaviours or
positive indicators. The
elaboration is an attempt to help assessors to better understand the scope of
the marker. The better the
assessors understand the boundaries of performance, the more standardised
assessments will be. However, the
natural tendency is for assessors to look for the elaborating examples
specifically rather than use them to guide their judgement. The trainee is then assessed based on
how many of the example behaviours are observed. This is actually codified in the EASA
VENN. This approach is wrong. The broad sweep of normal behaviour
makes it impossible to describe every way a specific competence element might
be demonstrated by an individual.
Assessors must use their expertise and judgement.
Assessors will look
at performance and extract behaviour elements. These can be physical actions, gestures
and other non-verbal signals or speech acts. These elements represent the evidence
upon which an assessor will evaluate performance. The marker framework must be capable of
capturing those element deemed most significant in terms of performance
outcomes but must do so in a way such that multiple assessors will make the
same categorisation of observed acts: as far as possible, assessors should
place the same event in the same category.
Therefore, marker schemes must be validated as part of the initial
development phase of the EBT. To do
this, first, collect some segments of crew performance on video. Next, SMEs who are fully conversant with
the marker examine the video and identify the significant behaviour
elements. These are then
categorised using the markers. Only
those elements that are unanimously agreed upon by the project team are retained
for phase 2. Next, small groups of
potential assessors observe the videos and, independently, identify behaviour
elements and assign to markers. The
results are then compared with the SME benchmark. Elements assigned to the same category
by both SMEs and trial subjects can be ignored. Where elements are assigned to different
categories then consideration must be given to redesigning the category, either
through changing the definition of the marker or by better elaboration through
examples, including specifying what is NOT included under the marker.
EASA has not
published any evidence to suggest that the 9 competencies have been validated.
5.7 A Proposed Solution
If an airline wants
to develop its own assessment marker scheme, the following process will help:
Step 1. From the SMS, develop a model of current
and predicted operational hazards
Step 2. Construct a ��look up table�� of crew
competence (Fig 4.1 as an example)
Step 3. Cross reference ��look up table�� to
hazard model and verify coverage
Step 4. Identify critical skills to cope with
hazard model
Step 5. Identify elements of critical skill set
that are routinely observed during normal operations
Step 6. Construct
marker framework (category and descriptors)
Step 7. Cross
reference markers to ��look up table��
5.8 Conclusion
A competence
framework is a broad description of a set of behaviours and underpinning
knowledge associated with successful performance. A behavioural marker is a subset of a
competence that can be observed and assessed in the workplace. Markers generally comprise a top-level
label and definition supported by example behaviours. The examples are intended to clarify and
better communicate the intent of the marker. Markers must be validated before use.
6 Some Thoughts
on the idea of ��Knowledge�� as Competence
The introduction of a set of ��competencies�� against which to assess
pilot performance has involved some debate around the issue of a specific
��Knowledge�� competence. Although
not adopted by ICAO, it is included in the EASA framework for EBT. Its description and associated
��observable behaviours�� are listed in the table below.
|
Application of knowledge
(KNO) |
|
|
Description: |
Demonstrates knowledge
and understanding of relevant information, operating instructions, aircraft
systems and the operating environment |
|
OB 0.1 |
Demonstrates practical
and applicable knowledge of limitations and systems and their interaction |
|
OB 0.2 |
Demonstrates the required
knowledge of published operating instructions |
|
OB 0.3 |
Demonstrates knowledge of
the physical environment, the air traffic environment and the operational
infrastructure (including air traffic routings, weather, airports) |
|
OB 0.4 |
Demonstrates appropriate
knowledge of applicable legislation. |
|
OB 0.5 |
Knows where to source
required information |
|
OB 0.6 |
Demonstrates a positive
interest in acquiring knowledge |
|
OB 0.7 |
Is able to apply
knowledge effectively |
The list of OBs is supposed to represent statements of observable
performance against which an individual��s competence can be assessed. OBs 0.1, 0.2 and 0.4 relate to the
simple recall of information: limitations, systems functioning, interactions
between systems, operating instructions and legislation. OB 0.3 relates to recall of information
particular to a destination. The
remaining 3 OBs do not flow from the top-level description and appear to be
after-thoughts. OB 0.5 points to a
need to have efficient search methods to find information while OB 0.6 reflects
an attitude towards study or maintaining currency.
The competence description positions ��knowledge�� as little more than
information contained in textual artefacts. However, OB 0.7 suggests that, to
be competent, you must be able to ��apply�� knowledge ��effectively��. But what does that mean?
It is a convention to classify knowledge as either declarative or
procedural. In essence, the former
describes what we can say and the latter describes what we can do. The declarative/procedural dichotomy is
not new and the first 4 OBs listed in the table are examples of what we would
consider declarative knowledge.
Although ��apply knowledge�� nods towards the procedural side of things,
it is too vague a statement to be of any real use. What we are really interested in is how
do we ��apply�� knowledge? To what
do we ��apply�� it?
Ohlsson, in his book ��Deep Learning��, prefers the term ��process�� to
procedural. In his view,
declarative knowledge is more than whatever can be recalled from memory and
recited. Rather, it comprises
arrays of constraints that must be satisfied for any action or intervention in
the world to be considered legitimate or successful. His ��process�� knowledge describes the
rule sets needed to control action.
This formulation starts to get closer to a useful description of
��knowledge�� that could inform an approach to training and performance
measurement. Knowledge supports
action. Declarative knowledge is
used to establish the legitimacy of the current status of the task in relation
to our operational goal while process knowledge allows us to achieve congruence
between the actual and the desired states of the world. From this perspective, the ��Knowledge��
competence is an inadequate formulation.
Advances in neuroscience, and in study of the visual system in
particular, have resulted in significant changes in our understanding of how
the brain works. Historically, the
study of cognition was predicated on information flowing from the outside - the
surrounding world - to the brain, being processed and then out again through
action driven by routines stored in memory. It now seems that this might not be the
case.
For a moment I want you to close your eyes. I want you to recall the scene in front
of you at the point at which you closed your eyes. Picture in your mind
everything that was in your field of view.
Take a few moments to recreate the scene. Then open your eyes. What do you see? In all probability your answer will be
��I see what was there when I closed my eyes��. If there was a window in your field of
view you might notice that something has changed. The drift of clouds across the sky might
have changed the lighting conditions.
Essentially, though, the world is still how it was when you closed your
eyes. Or maybe not.
In your mind you constructed a view of the outside world and when you
opened your eyes you projected your internal. mental view onto the scene in
front of you. You then cross
checked to see if what you perceived matched your expectations. Neuroscience is increasing revealing
that, in terms of cognition, the flow is from the inside out and not the other
way around. Cognition is not simply
interrogating the sensory world and interpreting cues. Rather, it is a process of validating
expectations based on stored data and reconciling differences. So what does this mean for the idea of
��knowledge��.
The physicist, Carlo Rovelli, explores the nature of reality from the
perspective of quantum physics in his book ��Helgoland��. He makes the point that ��knowledge��
describes more than just a ��library�� of stored concepts, facts and rules. it is the very the process of
interacting with the world. In this
view, ��knowledge�� is a dynamic process of detecting discrepancies between the
projected and the encountered worlds and the actions taken to reconcile
differences. In this view the world
is not a static ��out there��, it is something that is created as part of achieving
our goals. Returning to Ohlsson, ��declarative�� knowledge can now be seen as a
repertoire of conditions, acquired through training and experience, that allow
us to detect differences between our projected expectations and our actual
encounters. In effect, declarative
knowledge is error detection.
Process knowledge describes the ways we reconfigure the world to achieve
our goals.
There are 2 significant implications that flow from this discussion for
the idea of ��competence�� as formulated in the ICAO/EASA model. First, the OBs that require simple
recall have nothing to do with ��knowledge��. They relate to unstable artefacts that
describe arbitrary constraints. To
be considered ��competent, I must, of course, perform within those
constraints. But I called them
unstable simply because technology and policies are not static. LOSA observations are littered with
supposed ��errors�� that merely reflect the fact that the pilot being observed
was working with an out of date framework of policy and procedures. Pilots can still fly aircraft but they
cannot necessarily recall the latest rule changes. Whilst rules, procedures and limitations
are important, making them the focus of performance assessment places an undue
emphasis on the easily-captured but, probably, less important aspects of
performance.
The second implication is that ��the ability to apply knowledge
effectively�� (OB 0.7) must be rendered meaningful. Technical, systems information is of use
not just because it allows a pilot to diagnose what has happened but
more because it supports the construction of expectations: it allows me to know
what I will see and, therefore, be able to tell if what is
happening is what is required. We
need to develop training that addresses how pilots create expectations during a
flight, how they detect ��errors�� between the expected and actual status, how
they diagnose the causes of any discrepancy and then, finally, how to intervene
to restore equilibrium. This is
��knowledge as action��. This is true
��competence��.
Finally, if knowledge really is action then it suggests that any
meaningful attempt to assess performance should concentrate more on the utility
of outcomes in relation to operational goals. An ability to recite chapter and verse
is evidence only of a reliable memory, not an indication of competence. Without a doubt, outcomes must be
validated against prevailing constraints - policies and rules - but that is the
final stage of performance, not its underpinning driver. This approach poses a serious challenge
to concepts such as ��situational awareness�� and ��error��. It seems that what will call SA is more
likely to be a reflection of the efficacy of our interventions in the world to
restore equilibrium. Errors are not
outcomes to be managed but, rather, are simply feedback signals. It is the status of the current task
that must be managed in order to remove the discrepant signal. And this is achieved by applying
��knowledge��.
7 Testing
7.1 Introduction
Defining performance standards in ISD not only requires us to develop a
set of objectives, it also forces us to consider how we will test students to
assure that they have reached the OPS.
Courses developed under CBTA will require formal tests but training
delivered under EBT has a loose association with testing. In this chapter we will exlore some of
the issues that arise from the problem of ��testing��.
7.2 Testing
of Declarative Knowledge
Declarative knowledge, in (very) simple terms, is content stored in memory
that can be recalled in response to a trigger. It is we typically measure in ground
school using written exams.
However, when wwe looked at competence models in Chapter 3 we saw that
some aspects of ��competence�� might not be amenable to direct observation and
should be sampled through other means, like a written test.
The standard method of testing knowledge in aviation is the Multiple
Choice Objective Question (MCOQs).
An MCOQ comprises a question ��stem�� and 4 responses. This question type lends itself to
testing ��concrete�� knowledge where there are agreed definitions, stated values
or some other form of recognised, correct answer. They are more difficult to deploy for
topics that are more discursive.
Crafting reliable MCOQs is difficult and, so, the effort required should
not be under-estimated.
Penalty marking is used in many exam systems as a way of penalising
guessing. If there are 4 responses
then there is a 25% probability of getting the question correct simply by
guessing. Penalty marking makes it
more profitable to NOT answer a question that simply guess.
7.3 Testing
Process Knowledge
Process knowledge contains the ��how�� to do something. Testing process knowledge can be done
through practical exercises or through mental simulations: ��armchair flying�� or
��what if�� scenarios.
The use of simulator exercises in pilot training both develops skills
but also renders process knowledge tangible. Simulator scenarios do require careful
design if process knowledge is to be reliably assessed and further discussion
of this aspect can be found in Chapter 6.
7.4 Managing
the Output from Tests
5.4.1 Summative Testing.
Tests used to establish overall performance against a benchmark are
known as summative tests. End of
course exams used to determine those who have passed a course as opposed to
those who have failed are summative tests.
Pilot Licensing exams, aircraft handling and instrument checks are
summative tests.
5.4.2 Formative Tests. This
category of test is used to establish the stage of development or progress of an individual and
identify any additional need for intervention by the trainer. A ��progress�� test falls into this category. In EBT, the EVAL phase is a formative
test in that it is diagnostic and should be used to identify development needs
that will be picked up in the SBT phase.
5.4.3 Criterion-referenced Tests.
Where a test result is compared to an external benchmark then it is
considered to be ��criterion-referenced��.
The published standards for aircraft handling accuracy are ��criteria��
that are applied to the observed performance to establish the acceptability of
that erformance.
5.4.4 Norm-referenced Tests.
Tests that compare results against a peer-group, as opposed to an
external benchmark, are Norm-referenced.
For example, it is often argued that different grading scals shoud be
used for pilots at different stages of their career. How can a new-hire straight from
ab-initio school be assessed using the same criteria as an experienced training
captain? Pyschometric tests are
classic examples of norm-referenced testing. The result of each applicant is compared
with a distribution of scores of similar applicants to determine their position
relative to a peer group.
5.5 What makes a valuable exam question?
A well-designed exam question should meet 2 requirements. First, it should be able to discriminate
between candidates based on ability.
Second, it should offer insight into any flaws in the candidate��s
understanding of the topic. This requires careful drafting of the question
responses.
If an exam question has a 100% pass rate then it is either too simple or
the item being tested is of no consequence: it isn��t worth testing in the first
place. On the other hand, a failure
rate greater than 20% suggest that either the question is too hard (or badly
written) or the course content is not aligned to the question topic.
7.5 Conclusion
Testing is often given little consideration in aviation training but the
design of effective testing regimes requires thought.
8 Developing Training Modules
8.1 Course Design
In
conventional course design, the next step is to assign the TOs to the specific
modules of training. The entry level of the course delegates will shape this
process. Having assigned the
objectives to the training module, the next step is to identify the most
appropriate training media.
The
complexity of the task or performance element itself is important. If an
activity is either so simple that it can be achieved without formal training or
if unsuccessful completion is inconsequential, then it is generally agreed that
no training is necessary.
We
need to distinguish, at this point, between training and qualification. On the
one hand, training skills and knowledge can be accomplished in fairly simple
training environments. On the other hand, in order to provide the best evidence
in support of the SC and to satisfy the requirements of the Authority, there
might be a requirement to use high-fidelity training devices, at least for
confirmation of proficiency.
It
is possible to match training to technology to training requirement through
tests of training transfer. Whereas it is possible to cover the bulk of
preparatory training through classroom or computer-based training, skills
development often requires practice in an appropriate environment. The level of
fidelity of the device (i.e. the extent to which the device mimics the real
world) does not necessarily correlate to the training benefit of the device.
One
final step in the course design process is that of establishing the depth of
training required. With reference to the TA, we can identify 3 properties of
each task in the listing:
• the frequency with
which an individual encounters that task during normal line operations,
• the difficulty
involved in completing the task successfully and
• the criticality of
the task in terms of overall safety.
The
output from this analysis will determine how much training time to allocate.
The analysis will also influence the checking regime. For example, activities that are
infrequently encountered but are critical may need more training time allocated
to them and might call for more frequent checking.
8.2 Training Documentation
The
following documentation should be provided for each training event:
Syllabus.
The syllabus is a list of TOs covered by the course.
Curriculum.
The curriculum document describes the course in terms of its organisation. The curriculum
describes how TOs are allocated to individual sessions and links TOs to
training media.
Lesson
Plan. Individual lesson plans will be required for each training session. The
lesson plan provides the framework within which the instructor conducts the
training session.
8.3 Event Design under EBT
EBT
requires airlines to have a methodology for designing the various modules
called for under the regulation.
These modules are the Manoeuvres Training (MT), the Evaluation (EVAL and
the Scenario-based Training (SBT).
The MT module offers pilots the opportunity to rehearse critical or
infrequently-performed manoeuvres.
It is limited in its scope for data capture. The EVAL and SBT elements are LOFT
scenarios based around a table of requirements. They differ in that the EVAL element is
seen as diagnostic and the SBT as primarily training with space for the
remediation of issues identified in the EVAL. Events from the training topic table can
be spread across the EVAL and SBT elements but are handled differently in each
case.
The
EVAL and SBT modules of EBT represent design activities but differ from
conventional training module design in that they require an operator to
construct profiles that allow trainees to accomplish tasks derived from
analysis of operations. Because of
the range of system diagnostic
messages presented by modern generations of aircraft and the variety of
approach designs in the operational environment, there is insufficient training
resource available to rehearse every possible event.
8.3.1 Malfunction Clustering
The
process of clustering malfunctions is a discrete activity that can be
undertaken early in the EBT
project. First, generate a list of
possible malfunctions (using OEM documentation for reference). Retain those items that place a
significant demand on the crew. By
demand, you must consider those items that require active intervention, require
additional physical and/or mental effort and also any malfunction that degrades
aircraft handling.
Each
retained malfunction is then assessed against a set of criteria:
• Immediacy
(requires immediate and urgent intervention or decision, time critical)
• Complexity
(recovery with multiple options or decision paths, can result in multiple
inoperative or degrade systems)
• Degradation of
aircraft control (in combination with abnormal handling characteristics)
• Loss of
instrumentation (degraded or alternative displays)
• Management of
consequences (impacts on task sharing/workload management/decision making, can
result in a significant increase in workload)
One
method that can be use is to compile a table of malfunctions with columns for
each of the criteria. The table is
then distributed to a sample of pilots, usually senior, experienced pilots. Acting in isolation (i.e. not in communication
with others), the sample of pilots rates each malfunction against the criteria
on a 5 point scale. For example, an
event might score 1 (low) on ��immediacy�� if there is no need to prioritise
action but a 5 (high) if the malfunction required an immediate response. The size of the sample of raters needed
is, in part, driven by availability.
As a rule of thumb, no less than 5 would be acceptable but 8-10 is
optimal.
The
exercise moderator collects the individual ratings and calculates an average
score for each malfunction/criteria combination. The information is fed back to the
raters who are now asked, having been given feedback on group performance,
would they change their score in any way.
The second set of responses is collected. The scores for the criteria are summed to provide a final ranking.
For
each aircraft system (ATA Chapter), the highest scoring malfunctions are
retained. Consideration might be
given to setting a threshold value and only those malfunctions scoring above
the threshold are retained.
The
final list of malfunctions should then be compared against the available
malfunctions represented in the simulator.
Where a high scoring malfunction cannot be presented in the simulator,
consideration should be given to using alternative training media to address
that event.
The
process for approach clustering follows a similar philosophy.
8.3.2 Designing Event Sets to Create Surprise.
��Surprise��,
as opposed to ��startle�� is one of the training topics included in training with
the intention of building pilot resilience or coping. Another scenario design requirement is
for there to be sufficient variability to ensure that crews cannot prepare for
an exercise and, thus, present a rehearsed performance. Surprise can be created by giving crews
an unexpected event to deal with or to introduce sufficient disturbance to the
normal routine that crews are constantly having to adjust. The ��threats�� collected during a LOSA
offer a rich source of real-world disturbances. The ��event set�� concept,
adapted from ATQP provides a vehicle for incorporating technical malfunctions
in a scenario.
The
EBT AMC/GM makes it clear that ��surprise�� events must be standardised and
developed by the project team, not left to individual trainers to concoct. Event sets can be constructed using the
malfunction clustering output. The
list of malfunctions can be divided into 3 groups based on their rankings. The first group comprises those that are
candidates for inclusion in training.
The second group comprises those middle raking events that cam be
managed in parallel with other activities.
The final group comprises the lowest-scoring events that still require
attention but are little more than distractors. For each scenario, a list is compiled
comprising a number of malfunctions from each set. The trainer selects one malfunction from
each set for inclusion in the scenario.
8.3.3

Building Scenarios
Figure 6.1
Under
EBT, both the EVAL and the SBT comprise a LOFT scenario that addresses training
topics contained in the table appropriate to the generation of aircraft in
service with the operator. In each
cycle, events included in the EVAL do not have have to be repeated in the SBT
module. Across a 3 year programme
all training topics must be addressed in either the EVAL or SBT modules. Training topics vary in terms of the
requires exposure rate. Some must
be included in each session, others must be addressed in each cycle (12 months)
and some are required once in 3 years.
The topics can be divided into 3 main classes: manoeuvres, technology
and conditions. The table below
illustrates this relationship:
|
|
Manoeuvre |
Technology |
Condition |
|
Each Event |
Unstable Approach Go around |
Automation Manual Control |
Adverse weather |
|
Each Cycle |
2D/3D Approaches |
Systems Management Malfunctions |
Adverse Wind Terrain Surface Conditions |
|
3 Yearly |
Wind shear Recovery Lost Communications |
Engine Failures Fire, Smoke and Fumes Navigation |
ATC Traffic Load sheet errors |
Table
6.1
Several
of the training topics are elements of performance and are attributes of how
crew deal with a scenario. For
example, ��CRM�� and ��Compliance�� (each event), ��surprise�� and ��workload�� (each
cycle). Some, like ATC and load
sheet errors, are examples of threats and can be included in scenarios rather
than be the subject of a scenario.
The cell ��each cycle/technology�� will be informed by the output from the
malfunction clustering exercise.
Across a 3 year programme, crews should be exposed to malfunctions that
differ in terms of the criteria
listed in 6.3.1. The ��manoeuvres�� cells will be largely shaped by the approach
clustering exercise. The manoeuvres
column divides into departure and arrival events.
When
building scenarios, multiple topics can be incorporated into single
episodes. For example, ��adverse
weather��, ��unstable approach�� and ��wind shear recovery�� can be combined to
create a situation that also addresses ��CRM��, ��surprise�� and ��Automation��. Some topics share features. For example, ��terrain�� and ��traffic��
both create prohibited spaces that must not be penetrated by the aircraft. They, thus, have metaphorical
equivalence. Management of either
requires ��CRM��, ��workload management��, coping with ��surprise�� and use of
��automation��.
8.3.4 Training for Uncertainty[1]
If
competence is essentially about performance, it follows that training should
provide opportunities to, first, act and then allow for reflection. This premise suggests that training
should be experiential whenever possible.
Figure 5.2 shows a template design for a forced choice event that formed
part of a recurrent simulator session.
On this occasion, the overall scenario was a standard company route with
the aircraft on the return leg to home base. The route passed close by a third
company destination. Fidelity was,
therefore, high. The trigger event
was a depressurisation, chosen because it happened to be a mandatory item to be
covered during this cycle. The
forced descent resulting from the technical problem meant that there was now
insufficient fuel to complete the remainder of the flight and so a diversion
was necessary. There were two
available airports. The first was
the company destination and the second was still acceptable, if a little
further away. The first steps in
the design of the activity, then, are to select a plausible story line (routine
company sector), establish a trigger event which forces a response and then
offer plausible alternatives. The
goal is to design an activity that has face validity, which means that the
scenario is sufficiently plausible such trainees can readily buy-in to the
activity. We are trying to
capitalise on learner motivation.
Trigger Event
Decision
1A Decision 1B
![]()
![]()
![]()
![]()
![]()
D2A D2B D3A D3B
![]()
![]()
![]()
Land
Figure
6.2. Scenario Structure
The
next step is to define the attributes of the destinations. Runway direction, length, available
navigation aids and surrounding topography were, in this case, set. The variables that can be manipulated
are usually associated with the weather.
Precipitation, visibility, wind strength and direction, implications for
braking action can all be controlled.
In this scenario, values were set such that no single destination or
runway was obvious but all conditions were plausible, again in an attempt to
establish face validity. The intent
was to create situations that trainees would find recognisable based on past
experience. Having created the
scenario. the next step was to consult a group of SMEs. Management pilots were asked to step
through the decision points and state the advantages and disadvantages for each
choice. They were also asked to
state what their preferred choice would be. The decision points are described in
Table 6.2.
The
responses from the management pilots were aggregated and the most frequently
cited reasons were used to create a table that could be used in the subsequent
exercise debrief. Interestingly,
the results were fed back to the management pilots and some were surprised that
their peers, first, sometimes opted for a different outcome and, second,
offered justifications that differed from theirs. Even subject matter experts do not
always agree. Table 9.3 contains an
example of the decision point strengths and weaknesses collected from the
management pilots.
|
Decision Point |
Action |
|
1A |
Land at Destination A |
|
1B |
Land at Destination B |
|
2A |
Execute Go Around and Second Approach to Destination A |
|
2B |
Divert to Destination B |
|
3A |
Make Approach to Runway 1 |
|
3B |
Make Approach to Runway 2 |
Table
6.2 Decision Points
The
planning described here was then used to construct a simulator profile. Rules were established to ensure that
the exercise always ended with a successful landing: we did not want crews to
fail as that would undermine the training value. The debrief was then conducted using the
SME framework so that crew could, first, declare their own decision-making
process and then compare with the thoughts of an expert group. However. it was made clear that there
was no correct solution.
|
Decision 1 |
Go to Destination 1 |
Not Go to Destination1 |
|
Really Should Consider |
On-line port so faster service recovery Crew more familiar than with destination 2 Closer than Destination 2 |
Weather close to minima Probability of a missed approach |
|
Might Also Consider |
Better able to deal with medical issues arising from
depressurisation. No terrain issues Auto-land capability Fuel availability Long runway |
No ILS on reciprocal runway Time available for preparation due to proximity Landing performance (wet runway with tailwind) |
Table
6.3 Decision Point Characteristics
The
point of the exercise was to explore decision making. Because of the way the exercise was
constructed, crew had to trade off options (into-wind runway with no ILS v ILS
with tailwind; descend over terrain in marginal weather v descend over sea),
prioritise (needs of injured passengers v probability of successful approach)
and consider future risk (fuel remaining if unable to land off first approach). They also had to fly the simulator and
deal with the procedural activity associated with the task. The framework is representative of a
LOFT scenario although possibly with some additional effort applied to
designing the decision points. It also represents a template that can be used
to map competence training goals onto technologies.
8.4 Competency Mapping
AMC8
ORO.FC.232 requires operators to map their competency framework onto scenarios
in order to verify that opportunities exist, across a 3 year programme, to
capture data against all competencies.
Within each EVAL/SBT module, pilots should be assessed against all
competencies but the mapping exercise provides a cross-check of coverage.
The
mapping exercise is undertaken by teams of SMEs. The aim of the exercise is to identify
those behaviours most clearly associate with success in the particular scenario
element
8.5 Conclusion
Curriculum
development is the process of translating the TA into delivered training. ATQP
demands that training is developed according to a methodology. Furthermore, the
training system must comply with the requirements of the SC in that it must be
fit for purpose and it must deliver a product that meets operational needs. In
this chapter we have summarised some of the key issues associated with
curriculum development and suggested a methodology for linking flight data to
training.
9 Constructing a Grade Scale
9.1 Introduction
Assessing
performance requires trainers to undertake 2 tasks. First, samples of behaviour are
collected and assigned to a category we call a ��marker��, discussed in the
previous chapter. Next, the
combined evidence in each category is assigned a value on a scale. For this we need a ��grade scale��. In this chapter we look at constructing
scales.
9.2 Reasons for Grading Performance
There are a number
of stakeholders in the ��grading�� process.
The operator will want to know if the pilot group is fit for purpose and
if there may be trends emerging in proficiency. The regulator will want to know if the
pilot group is legal. The pilots
themselves will want to know that they are performing to the standard required
or if they need development. The
trainers will want to know if they need to put in any additional work on an
individual.
These different
stakeholders have different informational needs. The intervals on a grade scale represent
��information�� about the candidate being observed. Unfortunately, it is difficult to
accommodate these differing needs in a single scale, which, for efficiency, is
what we are trying to do.
9.3 Examples of Grade Scales
We will discuss the
mechanics ��grading�� further in Chapter 6 but the fundamental concept that must
be grasped is that we are not ��measuring�� pilots in the same way we can measure
height or weight. We are assigning
them to a category. Therefore, the
categories we use must be useful in the sense that they provide information -
or intelligence - that can be used to validate the risk assessment or Safety
Case (SC)(see Chapter 3)
The NOTECHS
framework uses the following grade scale:
|
Very Poor |
Poor |
Acceptable |
Good |
Very Good |
|
Observed behaviour directly endangers flight safety |
Observed behaviour in other conditions could endanger flight safety |
Observed behaviour does not endanger flight safety but needs improvement |
Observed behaviour enhances flight safety |
Observed behaviour optimally enhances flight safety and could serve as an example for other pilots |
Here is another
grade scale:
5 �C Exemplary
Performance. Crew members act in a
manner which could be considered a role model for others. Standard suitable for selection as
instructors.
4 �C Expected
Performance. Crew members act in a
manner expected of competent, experienced line pilots. Any slips are corrected by the
individual concerned. Crew members
performance guarantees safe and efficient aircraft operation at all times.
3 �C Performance
Rectified During Debrief. Crew
members act in a generally safe and efficient manner. Any slips are usually corrected by
another crew member or an outside agency before an unsafe situation can
develop. Crew members are aware of
any shortcomings and can offer reasons and alternative courses of action when
questioned during debriefing.
2 �C Performance in
Need of Further Training. Crew
members act in a generally unsatisfactory manner such that potentially unsafe
or inefficient situations exist for too long before corrective action
taken. Crew members often unaware
of performance problems. Additional
training requirement generally more extensive than can be accomplished during
post-exercise debrief.
1 �C
Unsatisfactory. Crew members act in
a way which causes aircraft to be operated in an unsafe or inefficient
manner.
Finally, here is a
4 point scale:
1. Unsatisfactory, unsafe, illegal,
below published standard
2.
Not unsatisfactory but aspects of the performance demonstrated a lack of, or
incorrect, knowledge or an incorrect technique. The assessor must be able to identify a
specific aspect of performance in need of remediation. The training or checking event can be
signed off but the subsequent report will comment on the specific performance
issue.
3. No doubt about overall competence but
the performance may have prompted a need to discuss points of finesse and
general development. Any lapses,
errors or inefficient management were of a minor nature and did not affect the
overall flight. Manual handling
might be of a standard such that control inputs are readily apparent to a
trained observer. The behaviour may have caused the overall crew performance to
be inefficient or degraded although not disrupted.
4. A strong performance that showed that the individual was capable of operating to the desired standard and/or was deserving of praise.
The number of
intervals on a grade scale depends upon the purpose it is trying to
satisfy. For example,
if we simply need to verify that the pilot is legal to operate, a 2 interval scale
is sufficient: yes or no. If we
want to identify those pilots capable of rapid promotion to command, we need a
scale that can better discriminate between individuals. The key problem is that, as the number
of intervals increases, the degree of inter-rater reliability reduces: more
categories equals more noise. This
problem will be addressed in more detail in Chapter 9.
9.4 Constructing a Grade Scale
Step 1. Clarify the
reason for grading performance
Step 2. Decide on
the number of intervals needed to satisfy the requirement
Step 3. Define the
intervals using clear ��anchors��
Step 4. Test the
intervals by defining what does NOT fit in each category
Step 5. Using SMEs,
field test the grade scale
Step 6. Fine tune
interval boundaries
Step 7. Field test
with larger sample of assessors
Step 8. Publish
grade scale
Just as the marker
framework must be validated before roll out, equally, the grade scale must be
tested. Again, a group of SMEs must
assign a value to a performance and then trial subjects must assess a video and
assign a score for each marker.
Where the trial subjects and the SMEs agree, the evidence used by the
trial subjects should be checked.
Where the trial subjects score differ, the reasons should be
identified. Again, where consistent
discrepancies occur the solution might be to redesign the grade scale or to
rely on training and feedback to arrive at concordance.
9.5 Conclusion
A shift to a
competence approach to training requires, first, a specification of performance
expected of competent crew. We then
need a tool to capture observable subsets of competence and method of
categorising crew. It is important
to remember that a CM and an assessment marker are not the same. The latter is just a sub-set of the
former. The complete verification
of competence may require additional forms of testing.
10 The Conduct of Assessment
10.1 Introduction
Assessment
is a fundamental part of the training function. However, we do have an issue with
terminology in aviation. Generally
speaking, the term ��checking�� has negative connotations in airlines around the
world. The nature of airline
recurrent training has been discussed elsewhere in these notes and it is
important to remember that we are both verifying the suitability of a line
pilot for continued employment.
Assessment, in the context of EBT, involves capturing data about pilot
performance within the behavioural marker framework.
In
this chapter we look at the process of assessment and some of the common
pitfalls.
10.2 Using Markers
Assessment involves gathering samples of ��evidence��, aggregating them into related groups and then putting a value to the performance. Observing what happens before your very eyes is surprisingly difficult, but it is the basis of the assessment process. The ��evidence�� is what the pilots say and do while operating the aircraft. A fundamental principle of using marker frameworks is that if you do not see it happening, then you cannot use it as evidence. This is important because, as a trainer, you will have a set of expectations of what you think a competent crew will do during the exercise. If they fail to meet those expectations then you will form a negative impression. This problem is discussed further below. You must first of all understand the markers. The marker descriptions are not exhaustive lists of thing people do within that category of behaviour. They are pointers. However, the markers are intended to be mutually exclusive: a specific instance of behaviour should not be capable of being assigned to more than one marker. However, because behaviour is messy, a particular episode might not fit exclusively into a single category. The skill of an assessor is in teasing out the component parts of the event and attributing them to the appropriate category.
10.3 Observation of Performance
Assessment
is a 4-stage process and can be summarised as follows:
'ORCE' �C Observe, Record, Classify,
Evaluate.
Stage
1 �C Observe. The starting point for
assessment is simply watching what happens during the assessment session. This first step is, of course, nothing
new. It is the bread and butter of
flight training and always has been.
The context of observation needs some consideration, however. Working in the simulator will require
the assessor to manage the training event as well as watch the crew. This might mean that events are missed
as attention is diverted to the management task. Doing a Line Check from an operating
seat means that the assessor is also part of the operating crew and that will
change the dynamic of the assessment session.
Stage
2 �C Record. Again, using notes to
record a training event is nothing new. Your notes need to cover specific
aspects of performance against the markers. Individuals usually develop their own
techniques over time but the important point to remember is that your memory is
fallible so try to make key point notes as required. Also:
• Try to be discrete
�C try not to let crew see you writing.
• Do not attempt to
take transcript of event
After
the event, review your key points and elaborate while information is still
fresh in your memory. These first 2
stages are common to all pilot training and are not unique to assessment using
markers.
Stage 3 �C Classify. Stage 2 simply allows you to recall as much evidence as possible before it is lost. Evidence is the samples of behaviour you saw. Now you need to assign your observations to the marker categories. Of course, behaviour does not fall neatly into boxes and so, as a rule of thumb, use an example to support an assessment against the most relevant marker: the ��best fit�� concept. It is important that you read the marker description and fully understand its scope., including behaviours NOT included in the category. Unfamiliarity with the marker will result in unreliability.
Stage
4 �C Evaluate. Finally, review the
evidence you have collected for the marker and assign a grade using the grade
scale. At this stage you are
weighing up your evidence and assigning a grade that best describes the overall
performance of the individual against that marker. In most cases the evidence will show
some variation of quality and your assessment should not default to the worst
case. Unless you saw something that
was illegal or unsafe �C in which case the decision is made for you �C you should
apply your experience and expertise to judge the body of evidence and grade
accordingly. Your decision will be
borne out by the evidence you cite in the report to support the grade you give.
AMC3
ORO.FC.231(d)(1) describes Stage 4 of the process in these terms:
��Assess
and evaluate (grade): assess the performance by determining the root cause(s)
according to the competency framework. Low performance would normally indicate
the area of performance to be remediated in subsequent phases or modules. Evaluate
(grade) the performance by determining a grade for each competency using a
methodology defined by the operator. ��
This
formulation is problematic. Having
��evaluated�� - assigned a value - the instructor is then required to provide
developmental feedback to the trainee in order to resolve any deficiencies in
competence and to consolidate and further develop those behaviours that are
already being delivered to the required standard (see sidebar ��Pilot
Performance, Safety II and Debriefing for Success��). This might require skills of diagnosis.
The AMC appears to confuse these 2 tasks.
10.4 Assigning a Score to a Performance �C Sources of Assessor Unreliability in Evaluation
Grade
scales are as prone to misuse as are markers systems. The key problems we need to address are
a function of the scale itself and the personal biases assessors bring to the
process. The 2 main scale related
problems are:
Central
Tendency �C this describes the degree to which assessors award grades of
��average��. This is a function of
scale design.
Scale
Abuse - Assessors clip top and bottom grades, often using justifications such
as ��there is always room for improvement��.
Other assessors award half marks by putting check marks on boundaries
between scales. In effect, they
have added intervals to the scale and our assessments are no longer standard
across all assessors
The
main problems with assessor bias are:
Primacy
�C This psychological characteristic relates to the fact that, in memory,
performances of the same task tend to be stored only after they have been
through some sort of averaging process.
By this, I mean that we do not remember every single, specific
performance. Instead, we have a
��generalised�� version of the event in memory and we tend to only recall
specific aspects of the performance that stood out in some way. On way of ��standing out�� is to be the
first. Therefore, when observing someone
complete a task that we are, ourselves, familiar with, we can often give extra
weight to the first thing we saw and our assessment of the overall performance
is coloured accordingly.
Recency
�C The same as above but now it��s the last thing you saw as this is the freshest
in our memories.
Halo
Effect �C if the observed pilot is good at one thing then, by implication, they
must be good at all things (inverse = Horns Effect. If the candidate is bad at
one thing they must be bad at all things).
Halo effect comes into play in cases where we have little or no evidence
against a specific dimension. So,
say the pilot was good at ��Communication�� but, for some reason, we saw little
behaviour in the category of ��Handling stress��. Because we thought they were good in one
area, we would assume that they were good in other areas, too.
Prior
Knowledge - performance coloured by what you already know about the
person. In small airlines it is not
difficult to have knowledge of a candidate before they arrive for training. We also have the training folder to
read. Because we have knowledge
before the training event starts, this can influence the way we judge the
performance. So, if we think the
pilot is weak, we will be harder to please; if we like the pilot, we will make
allowances. As a result, we are not
applying the same standard across all pilots.
Personal
Preferences - performance coloured by your own view of the world. This can be a problem if the markers are
vague or poorly understood by the assessors. I end up making a judgement based on
what I think is important and then I write up the report to support my
conclusions. You can usually see
when personal preference is being applied because report narratives will lack
evidence to support conclusions, or the assessor will use statements like ��I
feel that���� or ��My gut reaction is����
Gate-keeper
Syndrome �C the longer you spend in training the harder you become to
please. This results in average
grade score declining over time.
These
problems can be avoided by having a thorough understanding of the intention of
each interval on the scale and then with a disciplined use of the scale. It is also important to understand that
the intervals on the scale are, in fact, categories of performance rather that than
equidistant points along a continuum.
They are classes and the candidate is assigned to a class based on their
performance. Understand the spirit
of the class and grade scale use will become more reliable. The golden rules of grading are:
• Stick to gathering
data during the performance.
• Do not evaluate
data until after the performance.
• Stick to the
markers.
• Cite your evidence
to support your conclusions
• Keep reminding
yourself that you are fallible!
10.5 The VENN Model
The
guidance material proposes the VENN model of handling evidence. Observers should review the
performance of the individual
against each of the competence markers.
For each marker the assessor must take into consideration how many of
the OBs were seen and how often they were used. The outcome of the performance is then
considered before the final grading is awarded, which reflects the lowest
ranking assessment. There are some
problems with this approach. First,
there are caveats in the VENN process that recognise that it might not be
appropriate to apply a specific OB in the context of the task being
observed. Therefore, missing data
must be accommodated in the process.
Although
markers are not supposed to be used as a checklist and the listed observable
behaviours are simply a representative subset, by default the list becomes a
checklist. The framing of the VENN
process, with the specific question ��how many?�� reinforces the problem. The quality of the performance will be
associated with the outcome and so the ��horns and halo�� bias will be introduced
(Section 8.4). The VENN model
should be used with caution.
10.6 A Note on Validity.
Markers
represent mental constructs. They
are simply concepts we use to cluster types of observed behaviour. One problem with assessment is that
constructs vary in their validity.
Validity is simply the degree to which what we say we are measuring is
what we are actually measuring.
Take, for example, Situational Awareness. Am I measuring some ability of the pilot
to project forward in time, based on all the currently-available information,
and to accurately estimate what the aircraft��s position and status will be in
comparison with some ideal model of what it should be? Or am I actually measuring the psychological
parameters of memory capacity, field dependency, stimulus response time etc?
Matthew Beaubien and his colleagues at the American Institutes for Research in Washington review 2 studies looking at the construct validity of ratings given to crews undertaking LOS training. Construct validity is the extent to which a test item or scale actually measures the quality, characteristic, skills etc it claims to be measuring. The first study involved 636 Boeing 757 crews and the second looked at the results for 837 crews. The crews were given a grade for their performance at each stage of flight. They were graded for their technical proficiency and for their use of CRM skills. The result? In both studies the conclusion was that the scores are not related to the constructs being assessed. Instead, scores reflected some overall impression of how the crew did at each stage of flight, not how they employed specific skills. Let me explain with an example from my own experience. A colleague working with a US carrier was telling me of their attempt to use digital data from a flight simulator to somehow automate the performance grading process. First they did a whole load of V1 cuts with different crews. Each crew was assessed by an experienced instructor and was graded using the standard assessment forms. At the same time, various parameters were being measured and recorded in the simulator in much the same way as we record aircraft data as part of a FOQA programme. Once they had enough data they then looked at the relationship between the instructor assessments and the digital data. At the end of the day it all came down to speed of response. The grades awarded by the assessors were all related to the speed with which the crew responded to the V1 cut. The faster you reacted, the better the grade. How you reacted, how you worked as a crew etc counted for little or nothing.
10.7 Conclusion
Unless
trainers and assessors have a thorough understanding of the marker framework
and the grade scale any attempts to collect data on performance will fail. The sources of unreliability discussed
above are common to all systems where an individual assigns a score to another
individual: this is not unique to aviation. In the next chapter we will look at how
we can use statistical methods to improve data reliability.
11 Instructor and Assessor Training, Qualification and Standardisation
11.1 Introduction
There is an emphasis on data
collection in both ATQP and EBT. In
order to provide reliable data in support of the SC there will be an increased
need for Instructors and Assessors to be trained to a consistent level and
periodically checked for standardisation. In this chapter we outline the
systems needed to meet the requirement.
In addition to training, there are additional requirements for both
assessment tools and also assessors to be validated and periodically
recalibrated.
The concepts described in this chapter can be readily introduced into an
airline given that the fundamentals are already contained in EASA-FCL. The
benefits of a more rigorous approach to instructor and assessor training would
accrue to any airline wishing to adopt the principles contained in this
chapter.
11.2 The Training of Instructors
EASA FCL.920 lists the ��competences�� required of an instructor. By coincidence, this illustrates nicely
the problems with the competence approach.
The previous guidance on instructor training outlined the ��Teaching and
Learning�� course, which went some way towards providing an instructional
framework for developing new trainers.
The old content has been incorporated into the framework as ��Knowledge��
requirements (see AMC1 to FCL.920).
Part of the problem with the existing provision is that there is an
implicit assumption that the target population for the course will be ab initio
flight instructor. Training
Captains involved in airline recurrent training will need specific modules that
look at the observation and assessment of competence markers. This chapter will not deal with the
initial qualification of trainers. An illustrative training curriculum is at
Annex A to Chapter 7.
The core skills and attitudes of an airline trainer are (see also Annex
C):
Briefing -
preparing candidates for an activity
Observation -
effective data collection
Analysis and
diagnosis - interpreting performance
Evaluation
(grading) - accurate assignment of scores
Debriefing -
providing feedback for development
Administration -
timely completion of procedural activity
Empathy -
appreciation of the requirements of the candidate
Specific exercises will be needed to develop the skill of debriefing
and, possibly, briefing.
Information about administration can be provided in manuals but the
importance of timely and accurate completion of administration tasks touches on
attitudes to the role of being a trainer.
The ability to develop a working relationship with a candidates and to
consider the performance from the candidate��s perspective is important.
11.3 How to Train Assessors
In order to ensure the reliability of assessment data, airlines, first,
will have to ensure that assessors are properly trained and standardised before
they undertake any assessment of crew.
Airlines will then need to have an on-going process of monitoring
assessor performance.
When an assessor assigns a score to a performance we need to be able to
check that the score is ��true��, i.e it reflects the performance of the observed
pilot and is not influenced by other factors, such as the types of bias
discussed in the previous chapter.
If we cannot establish if the score is ��true�� then the assessment system
is almost worthless. Sources of
unreliability are individual bias in assessors, faults in the design of the
assessment markers and the grade scale and the assessment situation. There is one final source of
unreliability; random chance. As we
will see later, there is always the risk that the score awarded for a
performance could be pure luck!
In Chapter 4 we saw that assessment requires samples of behaviour to be
collected, categorised and then evaluated.
The first problem we have is that, because of the variability of
behaviour in the workplace, it is not always simple to assign performance to a
category. Observers will witness a
stream of activity that is shaped by the airline��s procedural frameworks but is
shaped by the contingencies being handles by the crew in real time. We can segment performance into:
•
Acts: observable actions related to
the control of work not associated with an explanation.
•
Utterances: verbal comments related to
the conduct of work not associated with an act.
•
Narratives: sequences of acts and
utterances delivered as a performance
•
Interregna: Observable pauses with no
acts or utterances often only accessible through eye tracking.
Each of these units of performance can be delivered by an individuals or
may be the result of collaborative actions by the operating crew. The units will be related to the control
of the task and will have a force in that they will contribute to the
successful accomplishment of planned goals. They can, thus, be measured in terms of
effectiveness. The role of the
assessor is to identify the acts in the stream of behaviour and assign a value.
The task of evaluation - or assessing - is fundamental to the trainers��
role and it is important to clearly establish that data collection is secondary
to the task of performance coaching.
It is of no use simply to be able to accurately grade a performance if
we cannot then help the candidate to improve, where necessary. The observation of performance is a
skill as is the assignment of a grade.
Each skill need to be developed.
It is not sufficient to simply publish the assessment markers and the
grade scale and then assume that an experienced Training Captain or simulator
instructor will be able to use the tools reliably. It is recommended that a 1 day workshop
be conducted. In addition to the
assessment scheme and the grade scale, suitable training materials - typically
filmed performances - must be created.
A suggested framework for the day is given below:
Session 1. Overview of assessment, its purpose and importance.
Session 2. Review of the assessment framework. This includes a discussion of the
markers, their scope and limitations.
Session 3. Practical
Exercise 1. Observation of video to
identify behaviours. Individuals
gather examples of behaviour and share with the class. The samples are then categorised using
the markers.
Session 4. Practical Exercise 2. Repeat of Exercise 1 but now the class
individually collect and assign evidence and then share their evidence against
the nominated markers.
Session 5. Introduction to
Sources of Bias
Session 6. Review grade
scale. Discuss the design rationale
and the meaning of each category.
Session 7. Practical
Exercise 3. Constrained Observation (i.e. assessors look for 1 or 2 nominated
markers only) and assign to grade. Group discussion. Trainer collects grades from individuals
before sharing. Discuss scores at
extremes of the range and get delegates to share evidence in support of their
assigned grade.
Session 8. Practical
Exercise 4. Repeat Ex. 3 but with different sample of markers. Results shared
and discussed.
Session 9. Practical
Exercise 5. Observation. Group
consensus on result required. Class
to lead the discussion and exercise ends once agreement on grade is reached.
Session 10. Conclusion.
Opportunity for handle concerns and questions. Explanation of next steps.
The first 2 practical exercises in the proposed training course look at the ability of assessors to categorise observations. Exercises 3 and 4 look at grading of performance. Exercise 5 is, in effect, a final standardisation check. Categorisation and grading are 2 separate processes and the reliability of each needs to be established[2].
11.4 The Importance of Debriefing
Post-exercise debriefing is a fundamental part of pilot training and an
essential skill for pilot trainers, the more so now that EBT places increased
emphasis on the accurate diagnosis of performance issues. In addition, the eager take up of
��Safety II�� thinking, with its focus on ��what went right, not what went wrong��
suggests that trainers need to be able to help learners actually work out ��why
it went right and how to repeat it again next time��.
Praising correct performance is a form of reinforcement and can
consolidate the achievement of the trainee, and humans are hard-wired to learn
through mimicry. The Mirror Neurone
System (MNS) appears to exist for that purpose. Now, some confounding variables. Expert observers are often perfectly
able to gauge the overall quality of a performance but then struggle to
decompose the elements that contributed to their overall assessment: they are
��blind�� to the granularity of what is happening before them. Furthermore, being able to identify
��what went well�� may not offer any evolutionary benefit whereas being able to
detect the signals of impending failure will save your life. When we talk about doing things well, we
are often commenting on someone��s ability to recover a situation. Something must have been going, or about
to go, wrong for ��rightness�� to become apparent. Part of the problem, especially in
airline recurrent training, is that, when dealing with trained and proficient
crew, what we see is what we are expecting to see - which is a competent
performance. Our primary task is
validating proficiency, not looking for reasons to comment on ��better than
proficient��. We must also
guard against confusing ��correct�� with ��right��. Procedural compliance is doing things
��correctly�� but simply following SOPs is not really what we are talking
about. There are, though, some
acknowledged consummate performers.
With them, every encounter is an opportunity to learn. These are rare and, when they do occur,
airlines should spend time studying why they are exceptional.
We have a paradox, then. On
the one hand, we have in us the software that ought to allow us to copy good
performance but, on the other, we lack the tools to identify acts that offer an
incremental benefit on our current level of functioning. The debrief is the forum where we try to
solve this conundrum.
11.5 Classical Debriefing Structures
Probably the oldest framework for conducting a debrief is what could be
called the ��chronological�� approach.
The trainer talks through the timeline of the exercise, picking out
items for comment. The
chronological model is intuitive and probably flows from our innate tendency to
tell stories. And stories usually
start at the beginning and finish at the end. Unfortunately, it isn��t an efficient
vehicle for promoting learning.
The other common model, unfortunately commonly known as the sh*t
sandwich��, tries to tap into the emotional state of the trainee. The debrief starts with an aspect of the
performance that was noteworthy. Of
course, this could be considered ��positive reinforcement�� but the goal is
really to create a willingness to listen on the part of the trainee. Next, the key learning points are
addressed. By learning points, we
really mean what the trainee did wrong.
The debrief ends with some more positive comments so that the trainee
walks away with the feeling that it wasn��t all bad.
Today, the ��sandwich�� model receives universal bad press. A part of the problem is not the concept
but its use. It needs planning and,
of course, it is no more than a set of place holders, a sequence of points at
which the trainer needs to engage with the student. And it needs skill to deploy the technique successfully.
Much of the discussion of giving feedback is in the context of staff
workplace development. The models
offered tend to look at aggregate behaviour over time and are directed at
future development over time. In
aviation, we are concerned with immediate behaviour change. We are looking at what you just did and
what you need to think about the next time you go flying. The EBT approach also assumes that
performance deficiencies will be diagnosed and remedied. The goal is to bring about change in the
short term.
11.6 ��Safety II�� meets Elite Team Sports
Eric Hollnagel makes the point that success and failure can flow from
the same performance. Another
concept, that of non-ergodicity, suggests that, in simple terms, things never
happen the same way twice. The implication
of these two positions - Hollnagel and non-ergodicity - is that process and
outcome are independent of one another. The same process on a different day
might have a very different end result.
Therefore, the debrief of a performance needs to separate the outcome
from the process. That is where elite team sports come in.
In aviation, the work process can be broken down into sequences of
actions that have a start point and a goal. The goal might be the completion of a
procedure, say, or it might simply be arriving at a point where the next
sequence of actions can start. For
example, the end of the cruise segment is not the notional Top of Descent, it
is the point at which the aircraft and crew are ready to commence the descent
segment. In a team sport, the
��game�� can be broken down into equivalent sequences. By definition they will be more variable
than a flight profile. But there
will be start and end points. In
each sequence, the individual will have a role to play. They might be in direct
contact with activity by being active (in possession, being next to play), by
being in a supporting role or by being ready to respond to the opposition��s
play. Game play, then, is analogous
to procedural activity. The
question now becomes ��what were you doing in fulfilment of your role? Did it
work (if you were active)? Was it optimal (if you were in support)? Were you
effectively isolated (unable to fulfil your role)? The actual outcome (scored a point or
lost possession) is irrelevant.
In terms of the debrief, what we now want to know is, given the task
goal active at that moment, what did you do? what alternative courses of action
were available? why did you chose that particular course of action? Given the
outcome - good or bad doesn��t matter - is there anything you might change next
time?
But this isn��t where the learning occurs. What we really want to know is what cues
were the student using to guide the choice of actions? What counter signs were there that might
have caused doubt? This is where
the facilitator starts to get involved.
By directing the trainees attention to the signs that things were
working and, conversely, to the contra-indications, we reinforce the good
performance while fine tuning the sensitivity of the trainee to signals that suggest
that activity needs to be modified.
11.7 Diagnosis, Debriefing and Facilitation
If we now come back to the structure and purpose of the debrief, we are
presented with the same challenge as we faced with the ��sandwich�� model:
optimising the use of time. For
elite athletes, time spent analysing performance is actually part of the
job. More time is spent in analysis
than is probably consumed by the event itself. A key lesson from this is that
elite athletes are taught to ��own�� their debrief: if nothing else, it��s the way
to make sure you stay in the training group. Pilot debriefs are not designed to
optimise learning. The time
available is set by the programme, by the trainers�� contract (credit hours) or
even by the time of the transport home at the end of the day. Debriefing for learning, then, might
require a culture change in aviation.
That apart, we can start to map out what the structure might look
like. In common with the ��sandwich��
model, we need to have an understanding of how the trainee viewed events. A self-aware, perceptive trainee could
probably run their own debrief. But
there will be occasions where the trainee��s view is at odds with that of the
trainer. The size of the gap
between the trainee��s and the trainer��s perceptions will influence how the
debrief will need to be managed.
A common template for the debrief might be, first, to identify elements
of the performance (acts attributable to the trainee)) that had some meaningful
significance in relation to the overall exercise. We start the debrief, then, with
behaviour that repeatedly contributed to maintaining the overall standard. By getting the trainee to analyse their
performance in terms of goals, cues and options, and then linking to the
successful outcome, we are reinforcing the behaviours that work but, also,
further developing the trainees sensitivity to the operating environment. It would be helpful if there were
discernible differences in context for some of the episodes so that we can
explore the trainees ability to adapt to circumstances while maintaining a
consistent output. The point here
is that we want to look at consistent, repeated but replicable interventions.
Of course, we also need to address performance that suggested that
control was fragile. For most
refresher training events, we might be looking at just singular episodes that
are of concern. The trainer must,
first, be able to diagnose what was wrong with the performance or why the
outcome was not optimal. We also
need to identify other segments of the profile where the trainee��s performance
required similar inputs but the outcome was adequate. We now get the trainee to compare and
contrast the segments of the profile leading up to the outcome. We need the trainee to be able to
identify what change would have been required to maintain an acceptable
performance and why that might have worked, under the circumstances. Importantly, we want them to identify
the cues present in the aberrant segment that should have triggered a modified
intervention.
The debrief ends conventionally with the trainee reviewing the lessons
learnt and establishing future performance goals. The process can be mapped thus:
Establish Trainee��s Perspective
Reinforce positive contributors (plans, cues, actions, outcomes)
Address development needs (plans, cues, context variables, alternative
actions)
Consolidation
11.8 Instructor Concordance Assurance
Imagine, for a moment, a class of students for which we have details of their ages and their gender. Age is a form of parametric data. Technically, it is ratio data in that it starts at zero and the increments are of equal size. Someone who is 4 years old is twice the age of someone who is 2. I can calculate the average age of my class. I can look at the standard deviation to consider the spread of ages. Gender, though, is different. For simplicity��s sake, I can say that there are just 2 genders and the class will fall into one or the other. My data is non-parametric. It is an example of what we call categorical data. I can describe a specific gender as a % of the class, or as a ratio of males to females, say. But I cannot calculate an ��average gender��. The assessment markers and the grade scale are examples of categorical data.
EBT requires the natural variability seen in any subjective assessment system to be controlled. They have called this the Instructor Concordance Assurance Programme or ICAP. Concepts around inter-rater reliability, agreement and variability already exist but the terms are often used interchangeably in the research literature and do not have agreed definitions. So EASA has invented a single label: concordance. To illustrate the problem, consider this set of data:
Student A B C D E F G H I J
Trainer A 4 4 2 2 1 1 4 4 3 4
Trainer B 4 4 2 4 2 1 2 2 2 4
The table shows the scores awarded during a trial to examine the benefits of using a simulator profile in airline recruitment. The trial subjects were newly-graduated students from a flight school with no previous airline experience. Each subject flew the profile twice and, to control for learning effect, each trainer saw half the candidates on their first attempt and half on their second. The trainers were simply asked to observe the candidate and then answer this question:
On the basis of the observed performance the candidate is capable of passing the initial Type Rating
Inter-rater Reliability (IRR) relates to the extent to which 2 observers looking at the same item or event will assign it to the same category. In this case, my items are the trial subjects and the categories are the trainer��s opinions about likelihood of success. The simplest way to calculate IRR is to see how many times the trainers assigned subjects to the same category. In our case, it happened on 4 occasions (subjects A, B, F and J). An IRR score of 40% (or 0.4) would be unacceptable. But we have another problem. What is the possibility that the trainers assigned the same score purely by chance?
In EBT assessments, the evidence collected is assigned to categories represented by the markers. One component of a lack of ��concordance�� is the error induced by poor marker design. Ordinarily, this would be minimised by prototyping and field testing. There is no evidence of the ICAO/EASA competence framework or the EASA grade scales having been subject to field testing and no concordance data has been published.
Assessment is a 2 stage process. Having assigned behaviours to markers we then grade the performance, another act of categorisation. If we look at the scores for subjects E and possibly I the trainers are roughly in agreement about the probability of success. For D, G and H, however, they split either way. So, which trainer is correct? We need a method for calculating the degree of accuracy of grading. One way to do this is to compare the scores of assessors in training with a ��Gold Standard�� benchmark, usually agreed by management pilots or senior trainers.
A common misunderstanding in assessment is that grades are not equally-sized categories. First a single grade of ��1�� on any marker is a fail. Imagine that the student got 5s for the remaining 8 competencies, if this was actually parametric (interval) data, the average score would be 4.55. But that cannot happen. It is still a fail. However, if the candidate got, say 3x3s, 3x4s and 3x5s, it could be argued that the average grade was 4? Unfortunately, because the categories on the grade scale are, as the name implies, categories, we have no idea of their extent nor the distance between them (think ��buckets��, not ��rulers��).
When we assign a grade, the number assigned represents several bits of information. First, how much evidence was collected to underpin the score? Second, how accurately was the evidence assigned to a marker? Third, how accurately have I put a value to the performance? Finally, how much ��measurement error�� can be attributed to the competencies and the grading system? Recognising the scale of the problem, what can I do to assure concordance?
This picture illustrates a classic IRR problem. What is the probability that 2 radiographers looking at the same scan will assign a tumour to the correct category: benign or malignant? Getting this wrong would have serious implications for the patient. Most of the statistical tests developed to resolve problems like this were formulated to cope with these rather limited situations: 2 observers making yes/no decisions. We need something that can cope with multiple observers looking at 1 or 2 subjects and assessing their performance against up to 9 categories. One such test is the Rwg. You can get a calculator here:
By convention, a score of .8 on the Rwg shows acceptable IRR.
|
Marker |
1 |
2 |
3 |
4 |
5 |
N= |
|
A |
1.16 |
11.62 |
63.95 |
22.09 |
1.16 |
86 |
|
B |
0.9 |
34.23 |
50.45 |
14.41 |
0.0 |
111 |
To illustrate the scale of the problem, this table shows the % distribution of scores awarded on a series of assessor training workshops. All the candidates watched the same video.
It is probably advisable to calculate the Rwg statistic for the grading exercises, once we have started to achieve an acceptable level of agreement. Importantly, the statistics for the final standardisation exercise should be retained as part of the ICAP validation process. Rwg should also be calculated after any periodic recalibration activity.
So far we have only looked at the degree of consistency between assessors. It could be argued that this is enough. Provided our cadre of instructors are consistent the data they collect will have some value. However, it might simply mean that they are all consistently wrong. They might be marking too harshly or to generously. Now we need to look at their accuracy of grading. To do this we need to construct a ��Gold Standard��. Strange to believe but management pilots and senior trainers are often no more aligned in their views than their line trainer colleagues. Here is some ��live�� data from an attempt to construct a ��Gold Standard�� using management pilots as the expert judges.
Expert A B C D E F G
Communications 2 3 3 4 4 4 4
Systems Management n/o 4 4 3 2 3 4
(n/o = ��not observed��)
To construct a standard, the expert group would need to reach a consensus and we can now use this to check against the scores awarded by the trainee group. This will produce a set of data for those that agree with the benchmark and those that differ. As well as a rate for differences, we will will have data about the extent of spread. The question we now face is how much variation is tolerable? We still have the problem of ��measurement error�� and the effects of chance in assessment. Should we simply keep training until all assessors meet the gold standard? This now becomes a cost/benefit problem. Consider this set of trial grading data:
Competencies: A B C D E F G H I
Gold standard: 3 4 4 3 5 3 2 4 4
Trainee 1: 3 4 4 4 4 3 3 3 4
Trainee 2: 3 4 4 3 4 3 4 3 4
Trainee 3: 3 3 3 3 3 4 3 4 3
A simple way to calculate the accuracy of grading is to look at the Mean Average Difference (MAD) between the gold standard and the scores awarded. If we then divided by the maximum divergence (scale intervals -1) we can standardise the score and derive a value between 0 and 1. By then subtracting from 1 we can make the scale more intuitive in that the closer to 1 the more accurate the scoring.
Competencies: A B C D E F G H I
Gold standard: 3 4 4 3 5 3 2 4 4
Trainee 1: 3(0) 4(0) 4(0) 4(1) 4(1) 3(0) 3(1) 3(1) 4(0)
Trainee 2: 3(0) 4(0) 4(0) 3(0) 4(1) 3(0) 4(2) 3(1) 4(0)
Trainee 3: 3(0) 3(1) 3(1) 3(0) 3(2) 4(1) 3(1) 4(0) 3(1) MAD 0 0 .33 .33 1.33 .33 1.33 .66 .33
SMAD 0 .08 .08 .08 .33 .08 .33 .16 .08 1- SMAD 1 .92 .92 .92 .66 .92 .66 .84 .92
We need to consider a cut-off value to decide if the degree of accuracy in scoring is acceptable in that to achieve perfect congruence will probably be impossible in the time available for training Here is the SMAD calculated using actual scores from 45 simulator instructors grading a video exercise for which a gold standard had been agreed:
1-SMAD +1 +2 -1
Application of Procedures .88 6 0 16
Task Management .79 32 2 1
For Task Management only 18% of instructors agreed with the gold standard whereas for Application of Procedures it was 52%.. The table also shows the spread of score, with Task Management being most heavily skewed. It seems that a cut-off value of .85 on this statistic ought to indicate an acceptable level of grading accuracy. If we go back to the trial data, it seems that competences E and G are not being accurately graded. If we repeat the calculation by rows we are now looking at individual instructors. Whereas Trainees 1 and 2 are grading satisfactorily, Trainee 3 has a MAD score of .806, which suggests a borderline performance.
The use of Mean Average Difference, which fairly crude, still provides useful information that, if nothing else, will signal potential problems with the grading of specific markers and the performance of individual assessors. MAD should be used during training. The important point here is that all assessors are looking at the same performance. Also, they can be compared against an agreed benchmark if you have a gold standard. These conditions can only be achieved in a training situation.
Once we have rolled out the assessment system, the ICAP will need to track the performance of the assessor group in order to detect drift and any emergence of outliers. We now need a different type of statistical test to assure that the system is operating consistently. In the training context we are looking at situations where 2 or more assessors are looking at the same candidate. In the real world we have to be able to handle data from many trainers doing multiple assessments on different candidates. A useful test would be Gwet��s AC2. We are still dealing with categorical data but the test needs to be able to handle missing data as ��not observed�� (and, thus, ��missing��) is a legitimate response. At the end of each EBT cycle, data should be examined for consistency.
To sum up, Inter-rater reliability and accuracy of grading should be measured at the end of initial training and during periodic recalibration. Routine monitoring of assessor performance is required at the end of each EBT phase. Finally, I just want to add a comment about the VENN model recommended for use in assessment. The process actually requires 3 acts of categorisation: how many, how often and TEM outcomes. If we are to meet the requirements of the ICAP, each stage must be tested for IRR. This would give us 3 statistics. Even if we got an Rwg of .8 at each stage, that would an aggregate outcome of .512 (.8 x .8 x .8) for the whole process. This degree of variability is unacceptable.
In
statistics, Inter-rater Reliability (IRR), Agreement (IRA) and Variability are often
used interchangeably. IRR is more
often associated with assigning an observation to a category while IRA and
Variability are associated with the act of assigning a value to a performance.
The EASA RMG has introduced the single term ��concordance��, party because of the
problem of finding a terms that
translates easily into different languages.
The requirement to assure concordance places 2 duties on an
operator. First, we need to be able
to demonstrate how we have reduced opportunities for error in assignment of
performance to a category. Then we
need to show how we have reduced inaccuracies in grading to a minimum. In both cases, action is required at the
design stage, during training and in subsequent operational monitoring of the
performance of the assessment scheme.
Where an operator adopts an assessment framework developed by a third party,
the requirement to satisfy the requirements of concordance are not
removed. Careful design and testing
of markers and grade scales is required prior to launching into the training
system.
Effective training has been shown to harmonise assessors�� views. The programme outlined in 9.3 above is designed to achieve
standardisation. One method we can
also consider is using a ��gold standard�� to check for IRA in grading. A ��gold standard�� involves getting
a team of staff pilots or senior check pilots to observe a performance and
agree the standard. The video is
then used in assessor training and the scores of the group are compared against
the ��gold standard��. It is remarkably
difficult to arrive at complete agreement on grading, even when using senior pilots. Annex D contains the output from a ��gold
standard�� exercise for illustration. We need to remember that the ��gold
standard�� only applies in relation to the performance used to construct that
standard. We cannot construct a
��universal gold standard��. The
primary goal of the grading system must be to separate those in need of
significant remediation or withdrawal from operations from those whose
performance is acceptable.
Assessor performance
is not stable across time and so we need a system for routine checking of
scores awarded by the assessor cadre.
The problem we now have is that the data cannot be tested using the
methods we have used previously.
The data set now comprises 2 sub-sets: different subjects assessed by
more than one assessor and each assessor grading multiple subjects. Instructor re-calibration events, held
at least annually, will ensure that concordance remains within bounds.
11.9 Calibrating the Grading System (AMC1/GM2 ORO.FC.231(d)(2))
The EBT guidance proposes that the grading system be assessed for
accuracy once every 3 years. In
order to do this a sample of pilots will complete a profile comprising a set of
manoeuvres contained in Part-FCL Appendix 9. The minimum set is:
•
rejected take-off,
•
failure of critical engine between V1
& V2,
•
adherence to departure and arrival,
•
3D approaches down to a decision
height (DH) not less than 60 m (200 ft),
•
engine-out approach & go-around,
•
2D approach down to the MDH/A,
•
engine-out approach & go-around,
•
engine-out landing
The profile is assessed against Appendix 9 standards. This exercise will
create a benchmark of performance against the competencies PRO and FPM. The rate of grade 1 scores against these
markers in the validation exercise can then be compared with the rate found
across the 3 year
programme. Any significant
difference should be investigated.
Calibration of the grade scale assumes that the Appendix 9 manoeuvres
are an acceptable reference against which to compare the broader assessment
process. It attempts to limit drift
in assessor performance, which might reflect a hardening or softening of
attitudes. While the approach is
plausible, it still assumes that the assessment is conducted in accordance with
the rules and that the performance observed meets the requirement of validity.
11.10 Conclusion
The nature of the work of line trainers and check pilots needs to be
reflected in the training given.
Because of the need for reliable data as part of assessing the
effectiveness of training, increased emphasis must be placed on standardisation
and calibration. Statistical
methods are available.
11.11 Annex A
Suggested Instructor Training Objectives[3]
1.0 Fulfil Instructor/Examiner Roles
2.0 Manage Instructional Events
3.0 Deliver Instruction
4.0 Conduct Assessment
1.0 FULFIL INSTRUCTOR/EXAMINER ROLES
1.1 Fulfil Instructor Duties, Functions And Responsibilities
1.1.1 Maintains instructor standards
1.1.2 Applies company training policies and procedures
1.1.2.1 Reviews changes to aircraft specific reference materials
1.1.2.2 Attends scheduled company and Authority standardisation meetings
1.1.2.3 Reviews new, revised, and existing training and information
materials
1.1.3 Applies airline safety policies and procedures
1.2 Maintains Professional Qualification
1.2.1 Maintains professional qualifications for assigned aircraft
1.2.2 Satisfies recency of experience and training requirements for
assigned aircraft
1.2.3 Attends appropriate training courses
1.2.4 Maintains applicable special qualifications
1.2.5 Maintains applicable special instructor technical qualifications
1.2.6 Undergoes recurrent checks as required
1.3 Develops Facilitation Techniques/Skills
1.3.1 Applies effective principles of facilitation
1.3.1.1 Apply principles of adult learning to training events
1.3.1.2 Adapts methods of delivery to training situation
1.3.1.3 Adapts pace of delivery to student��s needs
1.3.2 Develops a positive instructor/student relationship
1.3.2.1 Develops student motivation toward learning
1.3.2.2 Manages barriers to effective learning
1.3.3 Applies effective use of training aids to enhance the learning
environment
1.3.3.1 Classroom media
1.3.3.2 Computer-based Training and multimedia
1.3.3.3 Training devices/aircraft
1.4 Develop Student Assessment Techniques/Skills
1.4.1 Student performance analysis
1.4.1.1 Analyse student performance
1.4.1.2 Identify causes of shortfall in performance
1.4.1.3 Determine course of action for deficiencies
1.4.2 Conduct effective assessment
1.4.2.1 Identify characteristics of different assessment situations
1.4.2.2 Demonstrate knowledge of the acceptable performance tolerances
1.4.2.3 Demonstrate knowledge of grading scale criteria
1.4.2.4 Assess student performance in different assessment situations
1.4.2.5 Conduct an LOE
1.5 Integrates Human Factors (HF)/Cockpit Resource Management (CRM)
1.5.1 Demonstrate the application of crew performance markers in
training
1.5.2 Apply the principles of CRM in all activities
1.6 Integrate ATQP Principles
1.6.1 Demonstrate knowledge of JARs and supporting explanatory material
applicable to ATQP
1.6.2 Demonstrate knowledge of the ATQP development process and
qualification standards
1.6.3 Exploit Task Analysis outputs in training management
1.6.3 Participates in training quality management process
1.6.4 Conduct a LOQE
1.7 Fulfil Examiner Duties, Functions and Responsibilities
2.0 MANAGE INSTRUCTIONAL EVENTS
2.1 Checks Training Schedule And Lesson Plans
2.1.1 Determine training events
2.1.2 Identify students
2.1.3 Identify specific training device
2.1.4 Verifies lesson plans are available for scheduled lesson
2.1.5 Reviews lesson plans
2.1.6 Prepares lesson plans
2.2 Collect Required Materials
2.2.1 Obtain training materials
2.2.2 Determine testing materials availability
2.2.3 Determine training aid availability
2.3 Review Training Materials
2.3.1 Confirm accuracy modify as necessary
2.3.2 Tailors instruction and/or facilitation techniques to meet pilot
needs
2.3.2.1 Relates new tasks to those previously learned
2.3.2.2 Relates new tasks to common experience levels and backgrounds
2.3.3 Enhance training materials with supplemental information
2.4 Set Up Training Facility For Instruction
2.4.1 Configure furniture and teaching aids
2.4.2 Ensure that instructional materials are available and usable
2.4.3 Evaluate environmental conditions
2.5 Operate Classroom Equipment
2.6 Operate Computer-based and/or Multimedia Equipment
2.7 Operate Part-task Trainers
2.8 Operate Fixed-base Trainer
2.9 Operate Full Flight Simulator
2.10 Operate Aircraft
2.11 Configure Scenario-based Training (LOFT/LOE)
2.11.1 Select scenario within current training phase
2.11.2 Configure trainer for the start of the lesson
2.11.3 Operate trainer in accordance with the lesson plan
2.12 Record Training Event
2.12.1 Complete required documentation
2.12.1 Complete training tracking documentation
2.12.1 Complete event evaluation forms accurately
2.12.1 Complete forms for rating or approval
2.12.1 Document unsatisfactory pilot performance or required remediation
2.12.2 Notify programmers of need for additional training
2.12.3 Notify Standards of need for additional training
2.13 Complete end-of-course summary reports
2.13.1 Complete report on effectiveness of training devices, if required
2.13.2 Complete report for end of courseware revisions and changes, if
required
2.14 Report Hardware Problems
2.14.1 Record equipment and courseware discrepancies
2,14.1.1 Note equipment problems in maintenance log
2.14.2 Notify Training Department of courseware problems
3.0 DELIVER INSTRUCTION
3.1 Conducts Training
3.1.1 Delivers Type Rating Training
3.1.2 Delivers Aircraft Recurrent Training
3.1.3 Delivers Specialist Training
3.2 Conduct a classroom training event
3.2.1 Utilise effective presentation skills to accomplish lesson
objectives
3.2.2 Utilise effective facilitation skills to accomplish lesson
objectives
3.2.3 Use communication skills appropriate for subject matter content
and delivery
3.2.4 Ask questions based on the objectives to determine the level of
comprehension
3.2.5 Provide performance-based feedback and analysis to improve
learning
3.2.6 Evaluate the successful completion of objectives at the end of the
module
3.2.7 Exhibit knowledge of subject matter content
3.2.8 Demonstrate knowledge of academic training methodologies
3.3 Brief Practical Training Event
3.3.1 Conduct pre-brief
3.3.1.1 Explain objectives for the session
3.3.1.2 Describe the specific performance items that will be trained
3.3.1.3 Describe the performance standards
3.3.1.4 Describe time constraints and the time compressible events
3.3.1.5 Address crew members questions and concerns
3.3.1.6 Address safety aspects of training event
3.4 Conduct Practical Training Event
3.4.1 Conduct Briefing
3.4.1.1 Follow briefing guide
3.4.1.2 Brief the objectives, scenario and standards
3.4.1.3 Brief CRM skill/objectives
3.4.2 Conduct scenario
3.4.2.1 Adhere to lesson plans, and instructor handbook
3.4.2.2 Adhere to the scenario script
3.4.2.3 Act as a facilitator while fulfilling other roles
3.4.2.4 Evaluate CRM performance
3.4.2.5 Evaluate adherence to company operating procedures and standards
3.4.3 Terminate event
3.5 Debrief Practical Event
3.5.1 Review crew members�� performance against lesson objectives
3.5.2 Establish the standard of performance
3.5.3 Utilise effective facilitation skills and techniques to elicit
trainee analysis of performance
and methods of improvement
3.5.3 Debrief compliance/noncompliance with company priorities,
policies, and procedures
3.5.4 Review successes and identify a strategy for improvement
implementation
3.5.5 Evaluate CRM performance citing specific examples
3.5.8 Apply procedure and manoeuvre standards
3.5.9 Apply grading scale criteria
3.6 Coordinate remediation procedures
3.6.1 Discuss performance shortcomings and remediation steps fully with
trainee
4.0 CONDUCTS ASSESSMENTS
4.1 Conducts Assessment In a Training Context
4.1.1 Apply assessment criteria
4.1.2 Adheres to assessment guidelines
4.1.3 Evaluates competency of motor skill required for accomplishment of
task
4.1.4 Evaluates performance of abnormal and emergency procedures
4.1.5 Evaluates CRM performance
4.1.6 Demonstrates knowledge of qualification standards
4.1.7 Applies grading scale criteria
4.1.8 Demonstrates ability to accomplish data collection requirements
4.1.9 Debrief performance
4.1.10 Record performance
4.2 Conducts Assessment in a Testing Context (LOE /OPC/LC)
4.2.1 Apply assessment criteria
4.2.1.1 Adheres to assessment guidelines
4.2.1.2 Assess technical skills
4.2.1.3 Assess CRM skills
4.2.2 Demonstrates knowledge of qualifications standards
4.2 2.1 Apply grading scale criteria
4.2.2.2 Demonstrates ability to accomplish data collection requirements
4.2.3 Verify level of performance against pass criteria
4.2.4 Debrief performance
4.2.5 Record assessment
4.2.6 Apply scenario-based assessment process
4.3 Conduct a LOQE
4.3.1 Extract LOQE task
4.3.2 Brief crew on LOQE process
4.3.3 Compile LOQE paperwork
4.3.4 Submit LOQE paperwork
11.12 Annex B
Policy
for the Administration of Trainers
A. Instructor
Training
Responsible
Person
Description
of training scheme
Syllabus
Course
Evaluation Process
[Results
of evaluation supplied to SC holder]
B.
Arrangements for third-party providers
Evidence
of compliance with company standards supplied to SC holder
Evaluation
[Results
of evaluation supplied to SC holder]
C.
Instructor Standardisation
Responsible
Person
Methodology
Validation
of Methodology
[Results
of Standardisation provided to SC holder]
D.
Remediation
Procedures
for handling non-compliant instructor
Procedure
for validation and renewal
Annex C to Chapter 9
Assessing Training Captains
Work Contexts:
Classroom delivering workshops
Simulator conducting checks
Simulator delivering training
Aircraft conducting checks
Aircraft delivering training
Evaluation requirements:
Core attributes:
Knowledgeable (about topic and about operating techniques; standardised
and operates to standards)
Enthusiastic (attitudinal goal; supports the intent of the training
event (does not undermine training))
Manages event well (includes effective briefing of the activity;
understands the activity)
Additional requirements;
Appropriate intervention (allows trainee to learn by mistakes; doesn��t
intervene too early in order to prevent error; does not allow unsafe state to
develop by intervening too late or by abrogating responsibility to trainee)
Accurate fault analysis (can work out why something happened not just
identify what went wrong)
Effective debriefing (trainee understands weaknesses and knows how to
remediate)
Accurate reporting (grades reflect performance, narrative supports
grade)
Professional management of training (no errors in paperwork;
understands requirements for
training and testing)
Annex D to Chapter 9
- Constructing the Gold
Standard.
Scores and supporting evidence from
a group of management pilots who observed the same video.
|
C CN |
2 |
RT- read back 07R when ATC mentioned 07L,
however the error was detected and then corrected. Wrong TWR freq was read back but not picked up by ATC. |
|
|
3 |
Clarified PM��s understanding of ATC requirements, AMOTT crossing height, Runway in use. |
|
|
3 |
Lack of assertiveness in descent (Mods, RWY
in use) No concern with SW 160/15 (on FO limits) |
|
|
4 |
Effective working relationship. |
|
|
4 |
Good job of prompting F/O over missed/misunderstood ATC instructions & compliance. |
|
|
4 |
Strong oversight
of the operation observed. Clarified and confirmed when FO did not initiate
action, state or otherwise recognize the following items: Briefing �C Diversion
Fuel MCP - Amott
restriction 250/F120 ATC - Runway Change |
|
|
4 |
Addressed FO��s errors, good prompting |
|
C FO |
2 |
Inconsistent performance with observed lapses that required supervision and prompting from CN to ensure compliance. |
|
|
3 |
Talked to charts not Captain during briefing ATC speed and altitude requirement at AMOTT
not acted upon till prompted (active Listening) Did not detect RWY change in ATC communication |
|
|
3 |
Lacked clarity |
|
|
3 |
Generally closer compliance with FCOM 3/FCTM guidance, and closer attention to ATC instructions would be beneficial for command course preparation. |
|
|
3 |
No comms prior to disconnecting AP |
|
|
3 |
Briefing was dis-jointed and the Alternate fuel was omitted until prompted by PM. |
|
|
3 |
Most points covered but sometimes needed
clarification Briefings not in logical sequence |
|
SM - CN |
2 |
Should have intervened with an incorrect MCP ALT setting by F/O. |
|
|
3 |
|
|
|
3 |
Incorrect Flap configuration protocol. |
|
|
4 |
Loaded 250/12000 into FMC Efficiently completed Runway change in FMC, Methodical |
|
|
4 |
Appropriate programming of FMC |
|
|
4 |
No comment |
|
|
|
Not observed |
C
= Communication
SM
= Systems Management
Chapter
10
Line
Checks and LOSA
10.1
Introduction
In
EBT-speak, the old Operators Annual Line Check is now the Line Evaluation of
Competence (LEC). GM1 ORO.FC.231(c)
states that ��data from the line evaluation of competence is important to
measure the effectiveness of the EBT programme in operations.�� GM1
ORO.FC.231(h) elaborates on this idea:
(b) The
LEC is considered a particularly important factor in the development,
maintenance and refinement of high operating standards, and can provide the
operator with a valuable indication of the usefulness of its training policy
and methods.
AMC1
ORO.FC.231(h) states that:
The
purpose of the LEC is to verify the capability of the flight crew member(s) to
undertake line operations, including preflight and post-flight activities as
specified in the operations manual. Therefore, the LEC should be performed in
the aircraft. The route should be representative of typical sectors undertaken
in normal operations��
So far,
so good and, in line with current practice, a Line Evaluator need not be an EBT
Instructor.
It is
probably fair to say that Line Checks (LC) are not highly regarded nor are they
necessarily considered to be the best use of time and money. I once heard a speaker from a US major
airline say that an LC cost the company US$1000 per pilot for which they got
little return, other than to satisfy the regulatory requirement. In his opinion, conducting LOSA offered
a better return. In fact, LOSA is
often contrasted with an LC in order to demonstrate its benefits. An LC is the archetypical example of
what is known as ��Observer Effect��.
In any testing or observational setting, the mere presence of an
observer affects the behaviour of those being observed. LOSA describes LCs as eliciting ��Angel��
performance rather than behaviour representative of normal line
operations. And that is very
true. In fact, this is just one of
many problems that degrades the LC as
measure of anything. Because
LOSA is considered unintrusive and non-jeopardy, the view is that the data
collected is more ��naturalistic��.
If we
go back to the references above, the LEC is ��particularly important��, should be
performed in an aircraft, on a representative sector and include pre- and
post-flight activities. Given it��s
importance, AMC1 ORO.FC.231(h)(3) then allows for the interval between
evaluations to be increased to:
(a) 2 years. In every cycle, one EVAL for each pilot
should be conducted by an EBT instructor (EBT instructors) who has (have) a
valid line evaluation of competence in the same operator;
The
existing EASA ATQP and FAA AQP regulations both make provision for increasing
the intervals between LCs. In fact,
I know of one major airline that planned to adopt ATQP simply to cut the number
of LCs but without meeting any of the other requirements. EBT, therefore, simply continues the
tradition of trying to reduce the burden of regulatory compliance.
The
problem I see with this easement is that, apart from the fact that does not
meet the spirit of the AMC, which is how to fulfil an important obligation, it
starts to change the nature of the EVAL phase. There is an implicit assumption that airlines
will take up the offer of an extension in GM1 ORO.FC.231(h)(4), which suggests
that opportunities to use non-EBT Instructor line evaluators may be limited due
to the limited number of LECs that are required (every 2 or 3 years), the
difficulties in observing the whole range of performance of competencies and
the lack of control of the environment during a line evaluation of competence
(note: these latter 2 reasons are general criticisms of LCs). Therefore, the
operator may need to use EBT instructors to maintain an acceptable level of
standardisation.
It gets
more interesting when we consider that it is possible to extend the validity of
the LEC to 3 years if, in addition to conducting the EVAL with an EBT
Instructor, the operator has a feedback process for monitoring line operations
which:
(1) identifies threats in the airline��s operating
environment;
(2) identifies threats within the airline��s operations;
(3) assesses the degree of transference of training to
the line operations;
(4) checks the quality and usability of procedures;
(5) identifies design problems in the human-machine
interface;
(6) understands pilots�� shortcuts and workarounds; and
(7) assesses safety margins.
This is
an interesting list. Items (1) and
(2), while they might be captured in an SMS Hazard Log, are worded in LOSA
terminology. Item (3) is a type of
training evaluation activity (see Dummies Guide 9). Item (4) looks like something a
Standards team might address while item (5) ought to be the domain of the
manufacturer. Item (6) shades into
identifying areas of non-compliance while item (7) looks a bit like tracking
Undesired Aircraft States. So, in
summary, if you tweak your SMS and implement LOSA you can go to 3-yearly
LECs. Is this a good thing?
Before
I answer that question, I want to go back to the airline that wanted to use
ATQP simply to cut the number of LCs it did each year. Quite by chance I met the Flight Ops
Inspector to whom the request had been made. Of course, he asked why they wanted to
cut and the response was much as you��d expect. They don��t give us anything useful. So, he turned the problem around. He suggested that, rather than sitting
passively and wait for things to happen, LCs be turned into active data
gathering opportunities. What
aspects of performance can you expect all pilots to demonstrate on every
LC? How much of that is significant
in terms of assessing the conduct of operations? Step 1 was to turn LCs into
standardised, active data gathering events. He then asked what other aspects of
normal line operation might be significant but not routinely seen on an
LC? This could form the basis of a
LOFT scenario. He then suggested that
the pilots be assigned to 2 groups.
One group would do the targeted observation LC supported by the purpose
built LOFT while the other group just did a standard LC. After one annual cycle, a trial group of
pilots would do the targeted LC with a 2 year interval together with the annual
LOFT. If the quality of the data
captured remained the same, then all pilots could switch across. I don��t think the airline was happy.
There
are 3 key lessons to take from this story.
The first is to recognise that assessment events are data sampling
opportunities but all will have drawbacks. The second is the importance of
taking an active, engineered approach to data collection. The third is to recognise that change
must be managed in accordance with a safety case or safety risk assessment. Which probably raises a concern about
the wisdom of substituting an LC with an EVAL, even if conducted by an EBT
Instructor, without a risk assessment first.
So,
what sort of normal operations sampling regime might we develop? The first thing we need to remember is
that, although I have been talking about ��data sampling opportunities�� the LC
and LEC are both qualifications and we still need to be able to sign off pilots
as fit for purpose. This is a
complication because, although LOSA is probably a better data collection
vehicle, it has historically been conducted in a de-identified manner. data is aggregated to give a general
overview of fleet or airline performance.
LOSA does not support the need to sign off individuals.
Another
problem with a conventional LOSA is
that it is unwieldy, time consuming and quite intrusive. The delay in processing the data and
generating findings induces a lag.
As one airline speaker commented at a LOSA conference that, by the time
you get the report, the problem you identified has gone away and new problems
are emerging. Airlines are never
static. So, we need something that
is nimble and generates feedback in a timely manner. We need LOSA-lite.
Pulling
the emerging threads together we can start to map out a cost/effective process
that meets the needs of accrediting line pilots, tracks existing and emerging
threats in a timely manner, monitors the conduct of normal operations and is
sensitive to the safety status of the operation. The process builds on existing
capability within the EBT framework.
The
first component is the LEC. The
objective of the LEC is to verify that the pilot under observation performs
within the normal operations framework.
In order to avoid mission creep, the Line Evaluator should, first,
verify compliance and, then, collect data determined by an analysis of
probability of data observation and its significance in terms of operational
success. In terms of the
Competencies, the scope of the Line Check should be constrained. Only those competencies that supported
the core of the operation should be assessed. PRO, COM, FPA, FPM and LTW are primary
candidates. The implication of that
last statement is that all check pilots should be trained in the use of
markers. Interestingly, when the UK
CAA introduced CRM assessment using NOTECHs, one FOI said to me that the
Authority saw the fact that Line Checkers would now receive some training for
their role would be a good thing.
Line Check Pilots were typically company appointments not needing a
qualification. A question that does
need to be answered relates to performance drift. Without periodic recalibration, how
quickly does performance on the line start to depart from the prescribed
processes? How quickly to
short-cuts and non-standard techniques emerge? Will periodic visits to a simulator be
sufficient to maintain compliance, give that the simulator asset is really
being targeted at a different requirement?
The
EVAL module forms the next element of the process. The EVAL is a LOFT scenario that is
supposed to run in real time and starts at ��pre-flight��. The guidance proposes that the scenario
does not present any unanticipated
malfunctions. We do need to
consider the cost/benefit of using the simulator to capture ��normal��
performance. Furthermore, the
purpose of the EVAL phase is to identify any need for skill remediation,
reinforcement, consolidation and development. This rather suggests that performance
needs to be probed in order to identify any weaknesses. Simple rehearsal of normal operations
would probably not extend individuals sufficiently nor diagnose any issues a
pilot might have. The EVAL should
present enough of a challenge to separate those with robust skills from those
in need of support. Again, we have
a risk of mission creep.
Both
ATQP and AQP include an element that is similar to the EVAL phase but serves a
different purpose. Under ATQP, the
Line Operations Simulation was a standardised LOFT scenario that was used to
generate a de-identified fleet-wide performance benchmark. The AQP ��First Look�� is, similarly, a
standardised scenario delivered in the simulator used to determine the extent
to which safety critical skills may have decayed since previous training and/or
checking, and will also provide a baseline for assessing degree of improvement
attributable to subsequent training.
Interestingly, this last function reflects the idea of training
transfer. Unlike LOE and ��First
Look��, which are de-identified and offer a fleet-wide snapshot, the EVAL phase
is deliberately intended to be diagnostic.
It relates to the individual.
The EBT EVAL module, if properly designed, offers an opportunity to
observe the competencies of PSD, WLM, LTW under normal circumstances.
The
final part of the jigsaw puzzle is what I called earlier LOSA-lite. Interestingly, ATQP talks of LOQE, which
is LOSA by a different name. I have
seen 2 full-scale LOSAs conducted in an airline. The first was based on a
��day-in-the-life�� sampling model - the number of sectors observed is equal to a
day��s flying - while the latter was the 50 sectors per fleet recommended in the
ICAO LOSA guide. Neither sampling
regime is underpinned by a methodology.
They are pragmatic solutions.
I then introduced a different model. Instead of once every 4 years we
experimented with a rolling programme of annual LOSA events, each one designed
to address a specific issue. The
standard LOSA methodology was used but, through trial and error, the optimum
sample was identified as 30 sectors with a pool of no less than 5 observers. We calculated that this approach
collected the same number of observations across a 4 year cycle but was less
intrusive and also represented a significant cost saving.
The
system I have described represents an integrated data capture framework that
exploits the strengths of each mode of sampling. the sampling rate is sensitive
enough to identify performance drift.
If managed through an SMS or Safety Case, it would allow for
modifications to Line Check intervals to provide assurance to the Authority
that the certification aspects were being met.
I want
to conclude by quickly looking at a couple of initiatives that try to pick up
on the fashion for Safety-II.
First, I attended a briefing where data was presented that looked at
using the competencies to not only categorise the quality failures picked up by
LOSA but also to identify behaviours that ��saved the day��. The concept had some merit but the
paradoxical finding the ��SA�� was the most frequent contributor to both failure
AND success suggests that the marker has issue with validity. American Airlines (1) have been looking
at using the Safety-II approach through their Learning and Improvement Team
initiative. I must confess that I
struggled to understand what they were actually doing until I realised that the
project was just a variation on conventional behaviour elicitation. Using techniques like Flanagan��s
Critical Incident method, they have compiled examples of performance that have
then been shoe-horned into a framework that maps on to the Safety-II framework. Ironically, this is the method that
should have been used to develop the EBT ��competencies��. I illustrate how to do this in (2). The initial method is the same but the
second stage involves using subject matter experts to complete a Card Sort
exercise to structure the sample into categories, which can then be used to
create performance markers. In my
explanation, the structure emerges from the data. In the AA application, the data is
forced to fit the world. However,
there is a possible philosophical issue that might need to be addressed. The AA LIT approach is at pains to
differentiate itself from LOSA.
LOSA, by design, captures departures from expectation: errors, if you
with. The LIT approach looks at what
crew do and takes these acts to be examples of ��things going right��. There is an explicit assumption that the
observed performance of the crew must contribute to the successful
outcome. However, those causal
relationships are post hoc. That is
not to say that classes of behaviour might not be associated with success. For example, we observed in LOSA data
that, while threat rates differed between clusters of ports, error rates were
constant. When we looked at error
management, crews operating into high threat ports detected more errors and managed
more to an inconsequential outcome than crews operating into the low-threat
ports. All very interesting but did
not explain ��why��? A content analysis of LOSA observer narratives found that
crew operating into high threat ports invested 3 times as much effort in simply
communicating about the current status of the approach as other crews (e.g.
��when I was here before ATC did x to us��.
They made twice as many comments about planning and anticipation (e.g.
��if this happens, you do x and I will do y��). There seemed to be an association
between behaviour and outcomes. But
that still doesn��t mean causation.
There is nothing to suggest that simply getting crews operating to the
low-threat ports to talk about different stuff would change the error
management rates. That said, I do
think that smart use of LOSA data ought to be able to inform an approach like
the LIT, supporting the design of more useful data collection tools.
One
final throw away, I wonder how many carriers use their competence framework as
an event coding taxonomy in the safety reporting system? This is not easy to do, but offers
another input to the Safety Case.
https://www.amazon.co.uk/Building-Safe-Systems-Aviation-Developers/dp/0754640213
12 System
Safety and Evaluation
Reference
A. Line Operational
Safety Auditing. ICAO doc 9803
12.1 Introduction
Closed-loop models
of training design that use data to verify that the delivered training results
in a competent workforce. There are 2 contexts in which we try to measure performance.
First, training systems have traditionally used tests to measure student
performance. Testing can be further distinguished between confirmation of
achievement in training and verification of competence to operate. Second, data
can also be collected to measure the effectiveness of the training system as a
whole. Under ATQP/EBT we also need to distinguish between data gathered in
support of the SC and data used during the routine management of training and
operations. Performance measurement, then, is a complex process.
The ATQP/EBT data
requirements will be met using both subjective and objective data sources
identified primarily through the SC.
ATQP/EBT requires airlines to build specific data collection events in
addition to the more traditional performance measurement activities. In Chapter
3 we saw that the SC comprises a set of claims and corroborating data. In this
chapter we will review the various sources of corroborating data. In the next chapter we will look
specifically at the design of training events.
12.2 An Overview of Training Evaluation
Monitoring the
performance of the training system has been a feature of ISD from the outset.
Traditionally, performance is ideally captured at 4 levels:
Level 1
Satisfaction. At this lowest level of measurement the satisfaction of the
students is recorded. Commonly known as ��Happy Sheets��, satisfaction is
captured through questions such as ��the course was interesting�� and ��the course
was useful��. Level 1 performance measurement is probably the most
commonly-found evaluation procedure.
Level 2
Achievement. At Level 2 we are attempting to measure to what extent the course
has changed student behaviour. The most common form of measure at Level 2 is
the written examination or practical test. Tests can be used to assess the
effectiveness of learning (i.e. extent to which trainees master the content)
and efficiency (i.e. the rate at which students become proficient). Tests in a
training context serve to verify progress and confirm that students achieve the
graduation standard..
Level 3 Transfer.
At Level 3 we are concerned with the extent to which achievement in the
learning environment transfers to the workplace. Level 3 events include initial
qualification, renewals and periodic checks.
Level 4
Organisational Benefit. Long considered the highest form of training system
evaluation, Level 4 procedures attempt to identify any general organisational
benefit arising from training. Data captured through occurrence reporting and
safety auditing can be seen as Level 4 activity.
12.3 Data Gathering and the SC
The SC verifies the
safety of the training system through the use of data. During the design of the
SC, various performance indicators will be identified and verified as
representing best evidence in support of the SC. The data available for
collection is predominantly subjective in that it relies upon observations by
assessors or is the product of collection tools. Furthermore, such is the spread of
performance in the operational environment, no single data collection tool can
hope to do more than capture a small sample of performance. To increase the
robustness of collected data we need to ensure that the process possesses
certain characteristics.
The first
characteristic is that of validity. For a data point to be valid, it must
capture the performance the test is intended to capture. Validity is concerned
with the extent to which the performance captured is representative of the
actual performance of interest to the organisation. The second characteristic,
reliability, is concerned with consistency across time. Any changes in the
performance of individuals between 2 sampling events should be the result of
the behaviour of the individuals and not an artefact of the testing regime. The
third characteristic of assessment is the criterion against which assessment is
conducted.
Any testing regime
needs to be standardised such that all personnel assessed are measured against
a common benchmark. The benchmark will be the qualification standards derived
from the TA. Finally, as well as having a common standard of performance, the
testing event itself must be standardised. To achieve this, ATQP/EBT requires
operators to have processes in place to train and standardise checking and
training staff. The testing regime must have:
•
A specified structure
•
A description of the elements to be tested/examined
•
A statement of the targets/standards to be attained
•
A description of the specific technical and procedural
knowledge and skills and
•
behavioural markers to be exhibited
The structure of
the testing regime is defined in the regulations and is outlined further below.
The remaining 3 points will be derived from the SC, the TA and the supporting
curricula.
12.4 The Data-gathering Structure
The minimum set of
events used to capture data in support of the SC is as follows:
•
OPC (ATQP only)
•
First Look
•
LOE
•
EVAL
•
SBT
•
MT
•
LOQE/LOSA
•
LC
•
FDM
The events listed
represent situations in which candidates are checked for continuing qualification to operate as well as
situations in which the SC is corroborated. It is important
to keep the
distinctions clear but, at the same time, we should also consider the need to
design each event
such that the broadest coverage of the operating environment is
achieved.
12.5 First Look/LOE
The ��First Look��
concept is intended to establish a baseline of performance on entry into the
recurrent training cycle. It takes
de-identified data and builds a fleet-wide benchmark. Performance is assessed at the end of
the event. Evaluation at this level
is closer to Level 2 in the model described in Section 7.2.
The process for
developing the LOE will be driven by the SC and will be discussed in more
detail in Chapter 8. Elements of
the TA will be ranked according to frequency and criticality. A skill set that
measures high on criticality but low on exposure would be a candidate for LOE.
From the SMS Hazard List, a representative set of critical operational
contingencies can be developed. The TNA will provide the training objectives to
be met. Focus group methods can be used to develop scenarios that have
comparative levels of complexity.
For each training
phase there will be a need for several scenarios in order to prevent crews
anticipating training and adapting their behaviour accordingly. Such behaviour
reduces the reliability of the data collected during training. Once the event
sets have been developed and
standardised,
instructors must then be provided with sufficient information and training in
order to ensure the consistent conduct of the LOE phase across all
participating instructors.
12.6 EVAL
The EVAL phase is
similar to ��First Look�� in that it establishes an entry standard but differs in
that it looks at individuals rather than groups of pilots. The event is used to
diagnose training needs that will be remediated in the SBT phase. Evaluation at this level is closer to Level
2 in the model described in Section 7.2.
12.7 SBT
The SBT is a
standardised event designed to evaluate trainee performance and validate
trainee proficiency. The event is
conducted in a simulator using realistic operationally based scenarios. It is
important to remember that the demands made by the SBT on the crew must remain
within normal operational contingencies and reflect representative line
operations. The requirements of validity, reliability and consistency apply.
The requirements of an SBT are that:
•
They are developed in accordance with a methodology
•
There is a process for approving event sets
•
There is a procedure for conducting the SBT
•
There is standardisation of instructors
Performance is
assessed at the end of the event. A
failure to deliver an acceptable performance in SBT will result in withdrawal
for operations for remedial training.
12.8 LOQE/LOSA
The ATQP
regulations make reference to Line Operation Quality Evaluation, which seems to
be a LOSA-like process. LOSA is
described in the Reference. The EBT
regulations make provisions for extensions to the annual Line Check (LC) if an airline has ��a feedback
system for monitoring line operations (e.g. LOQE/FOQA)��. Given that the LOSA process is already well-established
and is an acceptable methodology we will simply refer to LOSA in the rest of
this section. LOSA differs from
FOQA, which uses flight data. We
will discuss the use of flight data in the next section but we should stress
that the 2 initiatives are complementary, not a substitute for one
another. LOSA differs from the
previous data collection tools because it is essentially a process that
captures aspects of routine operations. Its purpose is to evaluate the overall
performance of the operation. As
such, it is heavily dependent on conditions on the day and is not a standardised
data collection tool in the sense of all candidates being assessed under the
same conditions. It dos look at those elements unable to be monitored by FDM.
The basic requirements of LOSA under ATQP/EBT are:
•
A mechanism for the identification of data to be
captured
•
A process for approval of the LOSA phase
•
Procedures for the conduct of the LOSA
•
A procedure for processing the data captured
It is important to
remember that LOSA is not a test of the crew and so should not be considered a
replacement for the LC.
The SC will be used
to establish key performance indicators from the operational environment that
can act as corroborating data. An analysis of the available FDM parameters will
then identify aspects of the operation not captured in FDM programme but
meriting attention. The next step is to develop an audit schedule comprising:
•
Events to be monitored
•
Standardised codes to capture quality of performance
•
Standardised codes to capture causal factors in the
event of sub-standard performance
•
Observed by appropriately qualified operator personnel
The aim of LOSA is
to provide a large sample of data. The number of sectors to be observed will be
determined by the sample size necessary for the results to be within the
required bounds of confidence set against the number of observers available.
The observation process should be non-interventional. The observer simply
observes and records. By using a standardised reporting structure, the
subsequent data analysis is made simpler. Observers will require training in
the use of the observation tools.
12.9 Annual Line Check (LC)
The ATQP
regulations make provision for an extension of the interval between annual line
checks to 2 years while EBT allows an interval of 3 years if a process like
LOSA is in place. The ��line
evaluation of competence�� is a confirmation of a pilots ability to undertake
normal operations.
Because of the
problem of ��observer effect��, where the presence of an observer influences the
behaviour of subjects being observed. it is best practice for the line check
pilot to use the observer seat wherever possible.
The fundamental
philosophy of CBT suggest that the LC should be included in the data gathering
process. This might require a
reshaping of the nature of the LC to better collect data that is common across
most flights conducted under normal operations.
12.10 Flight Data Monitoring (FDM) and Analysis
Assessment of
performance in the contexts discussed in this chapter represent subjective
assessment by observers. Even though assessment will be standardised and will
be undertaken against agreed, defined criteria, the process remains subjective.
The routine capture of flight data offers an opportunity to continuously
monitor aspects of workforce
performance in an objective sense. Therefore, FDM programmes are an
important source of SC data. Existing fight data will be used as part of the SC
construction to identify areas within the TA that warrant particular attention.
Data can be used monitor effectiveness of flight crew training and
qualification and justify any changes to training. However, just as event-based
training needs to be treated with care, so does the use of flight data. Despite its objective nature, recorded
flight data represents the outcome of the process of aircraft control and
management. The thought processes and rationale underpinning the manoeuvring
and configuration captured by the data remain obscure.
The use of ��leading
indicators�� can shape the nature of data collection and, increasingly, data
visualisation tools will form a part of data analysis.
12.11 Calibration Activity
The problems of
observer bias and the need for periodic standardisation and recalibration have
already been discussed. In terms of
broader systems safety there is a need for independent benchmarking of
assessment standards. While
statistical testing of assigned grades will identify individual assessors whose
performance is anomalous, there is a risk of ��grade inflation��, which means
that all assessors are consistently over-marking. This, the reported performance is not
representative of true competence
of the pilot group. The design of the grade scale offers the first opportunity
to benchmark. The lowest interval
on the scale is typically defined as ��unacceptable��. Because this interval is linked to an
agreed regulation or policy, it constitutes ��criterion-referenced��
assessment. The award of such a
score can be tested for accuracy.
Similarly, the next interval on the scale usually identifies a
performance that is in need of remediation. The accuracy of the analysis can be
interrogated and validated. This
interval could be considered ��quasi-criterion-referenced�� in that the need for
an intervention should be apparent to all assessors. The remaining intervals are
norm-referenced in that they require a comparison with the expected performance
of the pilot group as a whole.
Where LOSA is used
it is possible to use the LOSA observer group as independent auditors. Provided they have been trained and
standardised, LOSA observers can assess performance using markers and the
aggregated data can then provide a benchmark against which to compare the aggregated
performance of the assessor group.
12.12 Conclusion
ATQP requires
operators to collect robust data to validate the SC. As such, every data
gathering event must comply with the requirements of validity and reliability.
Traditional methods of checking and qualification will continue but will also
have to comply with a set of prescribed design requirements in order for the
training system to meet the requirement of contributing in an overt way to the
overall safety of the operation.
13 CRM
��There
is no specific requirement for annual recurrent CRM training in the
nonoperational
environment��.
Regulatory guidance for transition to EBT. Version 3.2. 1Q 2021
13.1 Introduction
It
has long been a principle that CRM should be included in all training but the manner
in which that aspiration might be accomplished has proven elusive. The shift towards a competence approach
to training now offers an opportunity to achieve the goal. this chapter briefly
discusses some of the implications and possible methodologies.
13.2 The Problem of Compliance
Existing
CRM regulations contain a list of topics that is, in part, historical but has
also been updated to incorporate emerging concepts. That said, it is not a coherent syllabus
of instruction linked to operational performance. Equally, the recurrent training syllabus
has not taken into account changes in pilot licensing exams (Human Performance
and Limitations) and changes in initial pilot training (multi-crew cooperation
training (MCC) and Multi-pilot License (MPL)). Operators are still left with a
compliance requirement under EBT.
However, the new framework does provide some flexibility.
The
regulatory guidance, when considering legacy CRM requirements, states:
��Management
system: CRM training should address hazards and risks identified by the
operator��s management system described in ORO.GEN.200.��
Elsewhere
in these notes reference has been made to using data sources such as LOSA and
the operator��s SMS to inform SBT design, for example. One of the biggest benefits of a true
EBT approach to training should be the better mapping of competence development
onto the operational demands.
13.3 An Approach to CRM Training
As
was discussed in Chapter 4, a competence model typically contains a description
of a performance linked to underpinning knowledge. The competence makers describe the
performance. The next step is to
map the CRM training requirements on to the markers. It is unlikely that a syllabus subject
cannot be linked to a marker.
The
next issue is one of deciding on content and delivery method. In Chapter 1 we saw that the entry level
of students determines the level of instruction needed. The content of a ��refresher�� CRM class
should be different to that of an initial course (not covered by EBT) and a
mature training system will have seen several training cycles completed. The primary goal of recurrent CRM should
be to provide an adequate explanation of the behaviour that underpins an
assessment marker. Any theoretical
knowledge should be limited to that needed to understand the marker. Once the underpinning knowledge
requirements have been met, further training could be limited to explanatory
case studies and updates on recent research.
The
selection of the delivery method used will be influenced by the effectiveness
of delivery, its cost/benefit and any need to track performance for regulatory
requirements or record keeping.
13.4 Outstanding Issues
Some
legacy CRM requirements will need addressing. These include:
Combined flight
deck/cabin crew training:
(A) effective
communication, coordination of tasks and functions of flight crew, cabin crew
and technical crew;
and
(B) mixed
multinational and cross-cultural flight crew, cabin crew and technical crew,
and their interaction, if applicable.
Safety culture/
company culture - can be covered in
combined training
Cultural
differences - can be covered in combined training
Resilience
Case studies -
safety newsletter?
For
reasons of efficiency it would make sense to combine the Combined CRM with the
requirement to deliver Emergency and Safety equipment training.
13.5 Conclusion
EBT
offers a significant opportunity to move CRM into a more operationally-relevant
environment but it still requires analysis and planning to be effective.
14 Project Management
14.1 Introduction
In
this chapter we discuss the process for moving to a structured approach to
training, including an illustrative Implementation Plan (IP). A template
document which might form the basis of a submission to an authority is at Annex
A to Chapter 2. It is important to remember that implementing ATQP or EBT is as
much a change management process as it is an administrative change. Therefore, it is important to consider
the level of communication that might be needed to make sure that the
transition is smooth. The chapter
is arranged in an approximate chronological sequence and could form the basis
of a project management plan. The
chapter also discusses some items that are additional to the guidance material
but are considered important in a mature training system.
The
first step in implementing a revised training management system is to appoint a
project manager. Depending on the
size of the operation, this might be a full-time job. The nominated person must understand the
ISD concept, be aware of the work associated with implementation, have access
to the necessary resources and also have the authority to make decisions and to
represent the operator in discussions with the NAA.
14.2 Phase 1 - Planning
Task
1.1 Initial contact with the NAA (EBT Checklist Task 1)
Different
NAAs will probably have different methods of applying for approval. However, it is strongly recommended that
the company FOI is involved from the outset. In addition to the formal application
(EBT Checklist Task 2), the guidance material suggests that a draft
implementation plan (IP) be provided.
Sections 1 and 2 of Annex A to this chapter should satisfy the
requirement for a draft IP
Task
1.2. Develop training cost model {Optional - additional to guidance material}
The
cost model is essential for ROI calculations. We establish the cost model at
the outset as it will be used in subsequent decision-making about training and
checking policy. Methods for constructing costings can be found in various
texts on cost accounting methods.
Task
1.3. Develop the Stage 1 Safety Case Structure (EBT Checklist Task 4). .This
task involves developing the template Safety Case (SC) by incorporating
existing company information into the framework. Whereas the SC is a specific
requirement in ATQP, EBT only refers to a safety risk assessment but does not
elaborate on the concept. The SC
structure satisfies the requirements of both regulations.
Further
guidance can be found in Chapter 3.
Task
1.4. Map the existing training provision on to the ATQP/EBT framework (EBT
Checklist Task 3 Gap Analysis)
This
step is an audit of current training to assess the existing processes and to
identify the changes needed. Change may be a requirement for a new training
component or processes or it might be a need to reshape existing
provision. In EBT this is known as
the Gap Analysis.
The
Gap Analysis, as a minimum, should comprise a list of the components needed to
run EBT together with their characteristics or requirements. The existing training system elements is
then mapped on to the list. For
each EBT element, the existing training component is then evaluated as being
compliant or in need of modification.
Where a component requires modification, the specific actions required
must be listed. Where an EBT
component has no equivalent in the current training system, this must be
declared. The Gap Analysis is used
to identify activity needed to satisfy the EBT requirement.
Task
1.5. Develop the Stage 1 Implementation Plan (EBT Checklist Task 3)
The
Stage 1 IP will be a deliverable for the NAA and will outline the assessment of
the current status, the analysis of requirements (Gap Analysis), the project
plan for implementing change including timescales, the change management plan
(communication with pilots, control structures) and a statement of identified
resources needed (accountable person, project lead, team members, IT, vendor
support). This should also include
the proposals for:
• Trainer
training and standardisation (OM D action)
• Module
development
• Transition
management and remediation
Major
Management Review 1
This
review is a major milestone. It
gives formal standing to the Implementation Plan and the Safety Case Stage
1. It outlines the planned
activities needed, timescales and resources. The financial implications of transition
should be discussed. Sign off from
the accountable person should be obtained prior to proceeding to further
development activity. Consideration should be given to crew communication at
this stage. NAA FOI should be
involved in this review.
14.3 Phase 2 - Development
Task
2.1. Develop the Task Analysis (TA) (ATQP) or Competence Framework
(CF)(EBT). (EBT Checklist Task 5)
(OM D action)
The
TA/CF is the bedrock of the system as it describes how your aircraft are flown.
It is also, in the case of the TA, the most time-consuming activity. It
requires access to all company manuals and also to some line pilots, trainers
and management pilots. The TA/CF should be signed off by the project manager.
This
task will develop the performance markers.
Further
guidance can be found in Chapter 4.
Task
2.2. Develop Qualification Standards/Grade Scale. (EBT Checklist Task 6)(OM D
action)
Qualification
standards are levels of proficiency expected of line pilots and are synonymous
with the grade scale in EBT. For
initial training, subordinate standards may be used to define performance at
graduation from training (TPS). Where a lesser standard is defined, the process
by which pilots will transition from the graduation to the line qualification
standard (OPS) will be identified. This will usually be in the form of structured
OJT (LFUS, for example)
This
task includes work associate with establishing the validity and reliability of
the behavioural markers and grade scale.
Further
guidance can be found in Chapter 5.
Task
2.3. Implement instructor and Examiner training and standardisation
Under
both ATQP and EBT all assessors will need to be trained and standardised. This
includes both CRM, technical skills and competency assessment. This step will
involve reviewing existing training, auditing training reports and advising on
changes to both.
This
task will include activity associated with calibration and standardisation of
assessors. Output from this
activity will be included in the SC
This
task will require initial work associated with the Instructor Congruence
Assurance Programme (ICAP)
Further
information can be found in Chapter 7.
Task
2.4. Complete Malfunction and Approach Clustering Activity
The
SC will need to include a process for reviewing malfunctions and approaches in
the event of future changes.
Task
2.5 Implement Module Design Process
LOE/EVAL
involves the use of the simulator as a proficiency assessment tool. This step
involves developing the methodology to be used in the identification of
critical skill sets and the creation of appropriate scenarios that provide the
opportunity to assess those skills.
It will also draw on the clustering exercise to develop Event Sets.
While
the MT element is comparatively straightforward, the EVAL and SBT elements need
to be coordinated to ensure coverage of training topics. One suggestion is that a rolling 3 year
road map is produced to guide each annual cycle. The design process must be described in
the IP and linked to the SC.
Task
2.6. Conduct trial of LOE(ATQP)/EVAL (EBT)
This
step establishes the current performance standard of the fleet and will be used
as the benchmark for assessing subsequent changes. Both the LOE and the EVAL
phase have a requirement to manage outcomes in the event of unacceptable
performance. Therefore, it is
suggested that the LOE/EVAL modules be run as tests of the management system
prior to attempting to go live.
Task
2.7. Review and adapt existing training. Curriculum development
Once
we have established standardised data gathering against the operational
benchmark, we can now review training and checking and identify possible
changes. These changes can be assessed against the training cost model. This
will include the introduction of the MT module and aligning existing sim
training with the SBT concept.
CRM
and SEP training should also be reviewed and a modified plan for future
training produced.
Task
2.8. Draft 2 of Safety Case and Implementation Plan
This
should include the first draft OM D.
Task
2.9. Review flight data availability, LPC, OPC and LC report formats and modify
as required
The
ATQP and EBT is based on using data to track safety and proficiency. This step
requires all available data sources to be assessed in terms of output validity
and reliability. This step may require existing soft data report formats (LC
for example) to be amended to provide better input to the Safety Case. We will
also need to review DFDR output.
Major
Review 2
This
major review will validate the components that have been developed in order to
implement ATQP/EBT. The steering group
will also review the road map for future training (Task 2.5) and the output
from the LOE/EVAL (Task 2.6). The
CF and the grade scale should now be communicated to crew (change management
plan).
{as
part the project management, interim reviews should be conducted at intervals
between Major Reviews 1 and 2}
(EBT
Checklist Task 7)
14.4 Phase 3 - Programme Launch
Task
3.1. For ��Mixed Implementation��,
substitute modules as appropriate.
Task
3.2. Map flight data and assessor-provided data onto TA. Identify gaps and
develop LOQE plan.
This
step involves reviewing the proficiency data available from LOEs, LPCs, OPCs,
DFDRs and any other assessment situations and then mapping data onto the task
analysis. The aim is to identify critical areas of the task analysis where
performance is not being captured. Where gaps are identified then LOQE/LOSA
tools need to be developed to provide complete coverage.
Task
3.3. Develop Safety Case Stage 2 and establish Performance Benchmark.
This
step involves bringing all the information together within a single entity
known as the Safety Case. The Safety Case confirms through data the following 2
propositions: the training system is fit for its purpose and the training
system delivers competent pilots to the line. The Performance Benchmark pulls
together existing data to establish the current position of the airline. All
changes to the training system must be assessed against this benchmark.
At
this point we are able to identify objective data-driven markers that capture
line pilot proficiency levels. We now need to identify operational performance
indicators that can be easily tracked on a daily basis but which can act as
early warning of skill degradation or some other form of sub-optimal
performance.
Task
3.4. Produce Documentation
Development
of management plans for training quality management, curriculum development and
evaluation, and remediation.
(EBT
Checklist Task 8)
Task
3.5. Model proposed changes to existing training and checking regime.
This
task involves using data to model possible changes to training event duration
and interval.
Major
Review 3
This
review will allow the steering group to sign off on the Implementation Plan and
submit full documentation to the NAA.
FOI in attendance.
Task
3.6. Produce Final Implementation Plan for submission.
(EBT
Checklist Task 9)
At
this point training shifts to a ��Mixed Implementation�� model with data
collected in support of the SC. The
process for approving the final EBT structure is agreed with the NAA.
14.5 Deliverables
The
following elements are required as part of the ATQP/EBT:
Implementation
Plan (IP)
The IP forms the basis of the final submission to the authority. The structure of the document has been established and will be developed in an iterative fashion as the project develops.
Safety
Case (SC)
The SC is a component of the IP but will be retained after IP submission as part of the training management process. The SC structure has been established and will be developed in an iterative manner.
Task
Analysis (including CRM markers) (TA)
The TA will comprise a database of behavioural statements defining the company flight process. Each statement will be linked to appropriate references in company manuals and will be supported by skill and knowledge objectives as required. The database forms part of the deliverable.
Training
Needs Analysis and audit of existing provision (TNA)
Although not specified in the Reference, the TNA is standard industry practice and allows the existing training provision to be checked for thoroughness against the TA and then identifies alternative training solutions.
Line
Operational Evaluation (LOE) event set development process and Model LOE
The LOE is a form of crew performance measure and comprises a simulated scenario based on tasks drawn from the TA. An LOE is allows the performance of all crew to be verified against the TA in a standardised manner. This deliverable will comprise a methodology for LOE event set identification, a method for developing scenarios, a method for establishing event set equivalence and an example event set.
Line
Operational Quality Evaluation (LOQE) development process and Model LOQE
The
LOQE is a non-jeopardy audit process that allows data to be collected in order
to verify crew performance against the TA. The LOQE allows data to be captured
in areas not covered by other processes such as OFDM. LOE, OPC or LC. This
deliverable will comprise a methodology for LOQE design. The methodology will
be validated through the conduct of a small-scale LOQE as part of ATQP
development.
Instructor
and Examiner training curricula and Staff Standardisation
This
deliverable comprises an audit of existing instructor and assessor training, a
review of trainer and assessor standardisation, the conduct of any new training
required under the Reference and development of revised training curricula.
Revised
performance capture/assessment formats (LOE, OPC. LPC forms and EBT
equivalents)
This deliverable includes a review of existing reporting formats (including a consideration of the implications of the shift to electronic forms), mapping data capture onto the requirements of the SC and recommending changes as appropriate.
Course
curricula
For all course affected by the shift to ATQP/EBT a revised curriculum will be produced.
Training
audit process
This deliverable comprises a methodology, based on the SC, that will underpin the future validity of the ATQP/EBT
Method
of Integration with flight data monitoring and analysis
This
deliverable will review current data collection methods, identify valid performance
indicators contained in the data, specify the manner in which data is to be
reported to training management and develop the methodology that will allow
data to be used to validate the SC.
14.6 Annex A
A
Draft Implementation Plan
Introduction
This
document fulfils the requirement described in Ref. ?. It describes the process
by which {client} will design, develop and implement a pilot recurrent training
programme in accordance with Ref A. The document is divides into 5 sections and
is supported by the Safety Case. The sections are:
Section
1.
Planning.
This section describes the process by which the ATQP/EBT was planned, how
decisions alerting to modifications to existing training were made and the
steps put in place to ensure a smooth transition from the previous training
regime to the ATQP./EBT
Section
2.
Criteria.
This section describe the construction and validation of performance measures
used to ensure that the implementation of ATQP/EBT delivers a robust and safe
training system.
Section
3.
Programme
of Implementation. This section describes the process of design, development
and execution of ATQP/EBT.
Section
4.
Oversight,
This section describes the processes and structure put in place to provide
oversight of the ATQP/EBT design, development and implementation.
Section
5.
Documentation.
This section contains supporting documentation associated with the
implementation of ATQP/EBT.
Section
1. Planning
1.1
Introduction
1.2
Project design
1.3
Data collection
1.4
Design modification
1.5
Execution
1.6
Review
Section
2. Criteria
2.1
Introduction
2.2
Safety Criteria
2.3
Competence Model
2.4
Qualification Standards / Assessment Framework (Grade Scale)
2.5
Training System Efficacy
Section
3. Programme of Implementation
3.1
Introduction
Design
Phase
TA
Assessment
Methods
LOE/EVAL
Development
LOQA/LOSA
Development
Implementation
Phase (SBT)
Data
collection
Remediation
Section
4. Oversight
4.1
Introduction
Design
phase
Steering
group reviews
Implementation
Phase
Post
Holder
Steering
group
Section
5. Documentation
5.1
Introduction
Implementation
Plan
Safety
Case
Methodologies
Audit
Methods
Section
6. Safety Case (see separate document)
15 The Safety Case - Managing Hazards and Risk in the Training System
(Note:
this chapter is framed around the ATQP requirement. EBT makes reference to safety risk
assessments but offer no clarification. The concept of a Safety Case is equally
applicable to EBT)
15.1 Introduction
In this chapter we
look at the nature and construction of the Safety Case (SC). A template
SC is at Annex A to
Chapter 3.
In a range of
different industrial and commercial settings, safety-critical and
safety-related systems are becoming increasingly integrated and increasingly
complex. At the same time, the consequences of failure can be enormous in terms
of loss, damage and harm. In order to maintain satisfactory oversight the
compliance regimes being developed to control the development, operation and
decommissioning of such systems is also becoming equally as complex. Of course,
an airline��s training department is not a piece of technology or a complex
installation. However, it can be seen as a production system. It represents a
configuration of assets designed to supply and sustain a competent workforce
that is compliant with regulator requirements. The assets comprise people and
technological devices. The configuration can include wholly owned and
sub-contracted components.
Furthermore, the
configuration can comprise assets at a fixed location as well as those
delivered via distributed media. The tool generally used to establish a valid
and reliable justification for activity associated with a complex project is
the Safety Case (SC). Reference B states that the SC is:
A documented body
of evidence that provides a demonstrable and valid justification that the
programme (ATQP) is adequately safe for the given type of operation. The SC
should encompass each phase of implementation of the programme and be
applicable over the lifetime of the programme that is to be overseen.
Specifically, the
ATQP guidance states that the SC must:
Demonstrate the
required level of safety
Minimise risks
during implementation and operation
Substantiate the
validity of the training and qualification standards resulting from the
shift to ATQP
Substantiate the
validity of any future new training
Despite its
widespread use, there remains no definitive statement of what constitutes a
safety case.
However, the following is offered as a working definition:
The purpose of a
safety case is to present a clear, comprehensive and defensible argument
supported by calculation and procedure that a system or installation will be
acceptably safe throughout its lifecycle.
The SC, then, is a
management document that provides a justification for the airlines�� system for
delivering trained personnel into service, sustaining existing skills and
identifying any changes in the skills-set required of line personnel.
Furthermore, the SC acts as the vehicle through which major changes to the
training system are project-managed and evaluated. The SC provides the
framework for a set of arguments that are proven by linking the goal of the
training system to the relevant data. Where an airline is considering
introducing ATQP, the SC will incorporate those elements required by the
regulator for approval of the ATQP and will form part of the Implementation
Plan. However, the SC also provides a mechanism for validating the safety of
training for non-ATQP airlines. The SC should be seen as a management document
that supports, not replaces, the Part D.
15.2 The Structure of the SC
The SC provides the
framework for identifying and collating data in order to manage any risks
associated with the conduct of training. The closed-loop nature of the ISD
model, in fact, incorporates many of the features of a SC and it could be
argued that the SC focuses attention on Transfer of Training and Organisational
Benefit (See Chapter 6) through the use of safety-related performance
indicators supported by hard data.
Broadly speaking, a
SC comprises 3 main components. First, it contains a set of goals or claims
that must be achieved or confirmed if the training system is to be considered
safe. Second, it contains classes of data or assumptions that are used to
support the top-level goals or claims. Finally, it includes a set of rules for
linking the data to the goals. In order to fulfil its purpose, the ATQP SC will
need to address 4 questions:
What top-level goals
need to be constructed?
What constitutes
reliable data?
What constitutes a
legitimate argument linking data and goals?
How will the SC
change over the lifecycle of the project?
15.3 Constructing the Top-level Goals
The implementation,
and continued conduct, of training under ATQP is predicated on an airline
providing reliable evidence that its training system will meet, and continue to
meet, a set of safety-related criteria. The aspirations of the training system
are captured in a set of statements that can be referred to as goals, claims or
high-level arguments depending upon the particular structured of SC the
operator chooses to adopt. Just as there is no single accepted definition of a
SC, so nor is there an agreed terminology for the components of a SC. It seems
to us that, in the context of a training system, the SC establishes a set of
claims about the performance of the training system. In order to verify the
truth of the claims, the system must meet a set of performance goals. In this
section we will look at claims and goals in more detail.
The starting point
for any discussion of claims must be the 4 criteria listed in the Introduction
above which are
contained in Reference A. However, an airline��s training system has to meet the
needs of several stakeholders in addition to the regulatory authority. First,
it must deliver a competent workforce for line operations. Second, it must
deliver training in a cost-effective manner. It must reflect changes in technology
and the operational environment.
Finally, because
ATQP provides a vehicle for manipulating the training system, the SC must be
able to support the rationale underpinning any such changes. The top-level
claims developed for the SC must be sufficiently broad reaching to accommodate
these diverse demands. A process for identifying Claims and Goals might include
the following stages:
1. Identify
stakeholders�� safety requirements. These will include the requirements of
the client (i.e.
the Flight Ops Dept), the regulator, any associated codes of
practice, standards
and identified risks.
2. Identify
stakeholders�� competence requirements.
3. Break down the
Claims into Goals and Sub-goals that must be met in order for the
Claim to be
considered true.
4. State any
assumptions made relating to requirements, environmental conditions,
operational
constraints etc.
5. Make explicit
which parts of the system relate to which goals.
6. Verify that the
initial requirements will be met
We can develop a set of claims
that must be met in order for ATQP/EBT to
succeed, some of
which might be:
The safety of
activities conducted during training is equal to, or greater than, that
achieved under the former system.
The risk of
training activity failure during implementation is as low as reasonably possible.
The risk of
training failure during continued operations is as low as reasonably
possible.
The level of
proficiency achieved at the end of training is appropriate for operational
needs.
The qualification
standards applied to trainees are valid and reliable.
Changes made to the
training regime are reliable.
Whilst clearly
related to the successful implementation of ATQP, these claims are still fairly
broad in their scope. However, they provide the starting point for the
identification of the goals that must be achieved if the claim is to be
considered true. Goals and sub-goals render claims demonstrable and verifiable.
They act as the focal points around which evidence aggregates. We will look at
the construction of goals by taking a specific claim:
Claim x
The level of
proficiency achieved at the end of training is appropriate for operational
needs.
In order to
establish the truth of this statement we need to establish the level of
proficiency required of line pilots and the level attained at the end of
training. We can frame these 2 requirements thus:
Goal x1
The Operational
Performance Standard (OPS) of qualified crew must be compliant with published
standards and requirements.
Goal x2
The output standard
from training meets the OPS
These can be
further elaborated:
Goal x1
The Operational
Performance Standard (OPS) of qualified crew must be compliant with published
standards and requirements.
Goal x1a. The OPS
is defined by operational requirements
Goal x1b. The OPS
is compliant with regulatory standards
Goal x2
The output standard
from training meets the OPS
Goal x2a.
Graduation standards comply with the OPS
Goal x2b. The
testing regime is valid and reliable
Remembering that
these claims, goals and sub-goals are for illustration only, they nonetheless
allow us to begin the process of identifying the best evidence needed to
validate the SC.
15.4 Collecting the Best Evidence
The component parts
of ATQP will, in the first instance, generate the evidence needed to support
the SC. In the following table we demonstrate how these components can be
linked to the SC.
OPS/FCL TA LOQE
LOE OPC LC
Goal x1a x
x
Goal x1b x
Goal x2a x
Goal x2b x x x
Examples of
evidence will include:
Examination scores
Instructor grades
Flight data
parameters
Course evaluation
data
Quality audit
reports
Safety Management
System reports
However, if the SC
is to be robust, then Claims should be established through the use of the best
available data. This, in turn, means that data sources should be open to
verification. It also means that alternative sources of data should be
identified and used wherever possible. If we apply an engineering paradigm,
then there are 5 areas of interest in terms of seeking the evidence we need to
demonstrate that our goals have been achieved and, therefore, that the SC
Claims are true. These are:
System Modelling.
what is the reliability of each component in the system?
Hazard
Identification. what are the hazards that have to be dealt with by the
system?
Causal Analysis.
what could cause the system to fail?
Consequence
Analysis. what would be the consequences of failure?
Risk Assessment.
what is the probability and severity of failure?
As we said earlier,
ATQP is a process of managing training and the training department is an
instance of system configured to meet a purpose. The engineering paradigm does
not map perfectly onto our needs in developing an SC but the concepts are
useful in establishing where to look for data.
15.5 Inference Rules
Having
operationalised our top-level claims as a set off goals and identified the
sources of best evidence, it way well be the case that goals and data need to
be linked by an inferential process. This may require the use of statistical
methods.
15.6 Phased SC Implementation
The final problem
we need to address in relation to the SC is how will it change over the
lifecycle of the project. There are 3 phases of implementation:
Phase 1. Applying
ATQP to training management
Phase 2.
Reconfiguring training
Phase 3. Change
Management
Phase 1 involves
the application of ATQP elements to the existing training system. In effect,
this involves shifting from a compliance regime to a data-driven regime. The
effectiveness of the training system is not measured in terms of its compliance
with regulatory requirements but, rather, in terms of its ability to meet
performance indicators linked to measured data.
Phase 2 involves
the manipulation of training. Based on acquired data, the training regime can
be altered in terms of its content, mode of delivery, length of trainee
exposure to training, mode of assessment and interval between assessments.
Phases 1 and 2, together, represent the full implementation of ATQP.
Phase 3 represents
the on-going need to track change in operations and the operating environment.
ATQP is not a static step-change in the mode of training delivery. It is a
dynamic, closed-loop mechanism for ensuring that the output from training meets
operational needs. Therefore, the system must be sensitive to change.
15.7 Conclusion
The SC is a
component part of the Implementation Plan. However, given its role in risk
management, it is likely that the SC will remain central to training
management. Fundamental to the successful construction of the SC is the
identification of valid claims which can be verified through reliable data.
15.8 Annex A
Outline Structure
of a Safety Case
1. Introduction
1.1 The Aims of the
Safety Case are to:
Demonstrate
that the company��s training scheme is fit for its purpose.
Demonstrate
that the training scheme ensures that the company is safe for
continued
operations.
To
provide a vehicle for the management of changes to the training scheme.
1.2 TOR��s of
responsible persons (All staff with a direct accountability for training)
1.2.1 ATQP/EBT
Postholder
Name, position and
TORs
1.2.2 Other
Accountabilities
Any other staff
with indirect responsibility
1.2.2.1 Regulatory
point of contact
1.3 Historical
Performance
How we measure
outputs from training
1.3.1 Evaluation
Systems
How we measure
performance of components of training system
1.4 Annual Data
1.4.1 Training Key
Performance Indicators (KPIs) {to be developed}
1.4.2 Proposed
Indicators
1.4.3 KPI
construction
1.4.3 KPI
Validation
2. Training Hazard
Management
{In this section
all potential hazards and effects are identified, assessed and controls are
established}
2.1 Failure to
identify training requirement
2.2 Failure to
identify impact of change
2.2.1 Change in
Operational Environment
2.2.2 Change in
Procedure or Technology
2.2.3 Change in
Training Provision
2.2.4 Change in
Personnel
2.3 Failure to
identify student deficiencies
2.4 Failure to
identify instructor deficiencies
2.5 Failure to
select appropriate training method
2.6 Failure to
evaluate training
2.7 Generic Risk
Mitigation Strategy
3. Training System
Policies and Objectives
{Statement of safety
requirements and standards that are applicable and how are they complied with}
3.1 Regulatory
Framework
3.2 Company
Policies
3.3 Training System
Goals
3.4 ATQP/EBT
3.5 Third-party
Training Providers
Parts 1-3 will form
the initial submission to the regulator.
4. The Training
Delivery System
{Organisation,
accountabilities and resources}
4.1 Training Design
Cycle
4.2 Task Analysis
4.2.1 Analysis
process
4.2.2 CRM skills
analysis
4.2.3 Task List
{ATQP requirement}
4.2.4 Competence
Framework {EBT requirement}
4.3 Standards
4.3.1 Existing
Standards
{Description of
current performance standards}
4.3.2 ATQP/EBT
Standards
{Proposed standards
under ATQP/EBT
Maintenance of
existing standards during transition}
4.4 ATQP/EBT
LOE/SBT design
Third party
training
4.5.1 Quality
control of training content
4.5.2 Quality
control of sub-contracted instructors/facilitators
4.6 Existing
Training
{Training programme
structure}
4.7 Training and
Checking Staff
4.7.2 Appointment
of Staff
4.7.3 Training of
Staff
4.7.4
Standardisation of Staff
4.7.5 Remedial
action and Disposal
4.8 ATQP/EBT
Implementation
{Audit trail}
4.9 Remedial
Training
4.9.1 Technical
Skills
4.9.2 Non-technical
Skills
5. Management of
Training
{Description of the
management process used by the airline to control training}
5.1 Monitoring
training system performance
5.1.1 Training
Management Reviews
5.1.1.1 Periodic
5.1.1.2 Ad-hoc
5.2 Identifying
impact of change
5.2.1 Regulatory
5.2.2 Technological
5.2.3 Procedural
5.2.4 Operational
5.3 Dealing with
sub-standard performance
5.4 Implementing
recovery plans
5.5 ATQP /EBT
Implementation Plan
6 Auditing the
Training System
{Methods for
continuous safety improvement}
6.1 Dependent
Auditing
6.1.1 Assessment
Grade Sheets
6.1.1.1 Technical
skills
6.1.1.2
Non-technical skills
6.1.1.3 Grade Sheet
Auditing
6.1.2 LOE design
6.1.2.1 Technical
Skills
6.1.2.2
Non-technical Skills
6.1.2.3 Grade Sheet
Auditing
6.2 Independent
Auditing
6.2.1 LOQA
6.2.2 LOSA
6.2.3 SMS
6.2.3.1 FOQA output
from the SMS
6.3 Airline
Internal Audit Manager
6.4 External Audit
6.5 Instructor
Standards
6.6 Validating
ATQP/EBT
7 Statement of
Fitness
7.1 Form of
Verification
7.2 Compliance
Matrix
8 References
9 Transitional Arrangements